By now, everyone knows that Twitter exploded at SXSW and everybody’s seen the Alexa charts. But this is mostly a mobile app, so pageview traffic is only part of the story. How fast is Twitter really growing?
I decided to find out by using Twitter’s founder Evan Williams himself, albeit indirectly. Since Ev’s Twitter history goes from message #28 in March 2006 to #8,281,991 about three hours ago, it’s a convenient snapshot of Twitter’s growth since it began. Update: The data from November 2006 to present is faulty, since they apparently switched to non-sequential IDs. More information below.
I threw it all in Excel and charted the sequential IDs and dates for each of Ev’s 1,226 messages. The moment SXSW started, Twitter’s growth curve changed radically and hasn’t slowed down. (The huge orange bar for March is only half the month.) But more interesting to me are two other dates: November 23, when Twitter’s growth rate sped up drastically and then on February 5, when the rate seriously slowed. Are there problems with my data? If so, I can’t find it. If you have any sense of what triggered those changes, please comment and let me know.
To help with your search, and any other visualization, I’ve posted the full Excel spreadsheet with inline charts and tables. Enjoy!
Note! The last three are cumulative charts, not month-to-month growth numbers. That means there were not 8 million messages sent this month, but 8 million total since Twitter started.
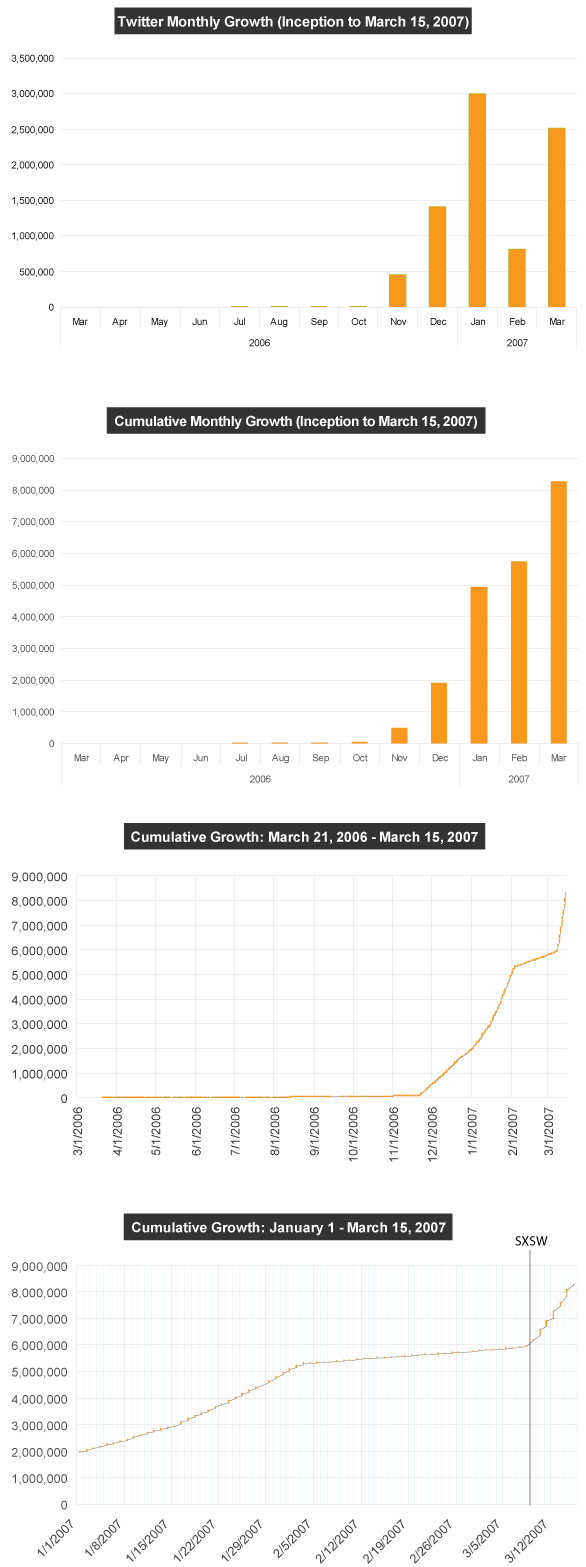
Update: Jason and I just discovered that the IDs since November 2006 have not been sequential, rendering these charts useless. The jumps in activity were largely artificial. Jason has more information.
nice.. the long tail in motion :)-
thanks for sharing !!
The slow down is probably due to Twitter hitting the performance wall. I know I had a lot of trouble posting to and receiving messages from Twitter during that period — so I lowered my usage of it until performance improved.
Hmm, it looks like November 23 was Thanksgiving. (Though I don’t understand why that would lead to a change in the growth rate.)
Maybe late November was when Twitter first starter to appear outside of the really early adopters, for example Scoble signed up 20 Nov?
I second the performance wall hypothesis. That’s when I started implementing my “connect twitter to arbitrary desktop apps” project (mostly just to practice Proto/VBA stuff, I don’t know why anyone would want every iTunes track to be a twitter message) Twitter was reaaaaaallly slow. I’d played with it a long time before then and it was snappy. I know in that couple weeks when I was playing with it, I personally would have sent several times more messages if it wasn’t lagging so bad.
I’m up to 100 followers after just 3 or 4 days. Started using it on day 1 of sxsw.
Very nice Andy. I love it when you run stats like these
A Many Eyes treatment of the same data. Not as pretty. I sourced the data back to here and hope you don’t mind.
http://services.alphaworks.ibm.com/manyeyes/view/SJjqGFsOtha61PEcjt5KF2-
Isn’t this better thought of as a growth rate, i.e. first derivative of what’s posted here?
http://tastic.brillig.org/~jwb/twitter.png
Not posting to be the internet jackass, but I think your data collection methodology is flawed, and this might explain the abnormalities you’re seeing.
It’s a mistake to assume that each sequential ID represents a single post in the system (unless you’re privy to back-end details, in which case I’ll shut up).
It’s probably safe to assume that the number is an auto-generated sequential ID of some kind, but we don’t know for sure by what amount this value is bumped up every time there’s a post made to the system. An id of 8,281,991 doesn’t mean 8,281,991 posts are in the system
So, here’s one plausible scenario that’s probably not “the truth”, but it illustrates my point. Twitter starts as a small application with a single MySQL database server. The table that stores the messages has an auto increment primary key that gets bumped up by one for each row inserted.
At some point, one database server isn’t enough. Twitter is an application that’s going to be sensitive to slave lag, so the team decides to go with MySQL 5’s multiple master feature which lets you have more than one master server.
One of the problems with multiple master servers is what happens if both servers receive an insert at exactly the same time that generates the same auto_increment primary key. The master/master synching voodoo pukes and corruption happens.
To get around this, the primary keys use a modulus. In a two master setup, one server generates odd keys, the other generates even keys. In a three master setup, each id is incremented by 3 with server 1 starting at 1, server 2 starting at 2 and server 3 starting at 3. Since the servers will always generate different primary keys, corruption is avoided.
With this setup, unless the traffic is evenly distributed among the database servers, the id is no longer an accurate count of how many posts are in the system at any one time.
Now, let’s throw in another wrinkle. If you’re smart, even if you only have a two or three master setup you use a higher modulus to make replicating new masters into the system a breeze. So, an application might only have two database servers, but their primary keys are being incremented by 5 each time, which will let the application scale up to five master servers without having to worry about re-jiggering the modulus each time you add a new server.
So, in this setup, even with even traffic distribution between the database servers, your “id as a representation of how many posts are in the system” is completely fucked. The November 23rd traffic spike could be when a system like this was bought online. The February 5 drop off could be a re-jiggering of a modulus that was, in retrospect, too high.
Other, less complicated, scenarios could involved a much high number being pushed into an auto_incrment field for some reason. Subsequent inserts would start at this new higher number.
I dig the graphs though (-:
Andy, the first surge is not on November 23. If you look closely, you’ll see that use quadruled on November 21 and multipled by a factor of 7-8 the day after. November 21 was the day Twitter launched the “six word memoir” promotion.
Use remained flat for the rest of the year. The effect on March 10 is unmistakeable: 20 times the use of the day before.
I started on 11/18. I think the Thanksgiving phenom is because people are in motion during the holiday and are reaching out to their friends. That’s what I did anyway…
Hey, I joined 11/20. I’ll take full credit.
Great graphs, thanks for posting them.
Thanks for taking time to do the work to generate these graphs. And get the ball rolling to look inside Twitter a little bit.
Alan: They’re almost certainly on a mysql backend with the default auto_increment stuff set. Which one should not do, for a variety of reasons:
http://joshua.schachter.org/2007/01/autoincrement.html
Joshua
First off, twitter does use autoincrement. They know they shouldn’t, but they do. They also only have on backend database so far. So Andy’s numbers look good from what i know of twitter’s setup.
The question of why the jumps? Those dates correspond to when good IM support was added, API’s where released and desktop apps where built, and when the signup process got streamlined. Before November you needed a mobile phone to join. Once that was dropped growth shot up.
That sounds like a definitive answer to me. Thanks, Rabble.
I assume they use something like PRIMARY KEY(msg_id) and KEY(user_id, twitter_dt).
under Innodb, if they had PRIMARY KEY(user_id, msg_id) and KEY(user_id, twitter_dt) it’d have to do far less disk seeks to do the join, because all of a user’s messasges would be in contiguous pages.
Alan, if what you say is accurate, then there should be a sudden *and permanent* jump in the slope of the line, due to a more collision-proof use of the primary key space. Rabble the authority here, so I’m assuming that auto_increment is in use.
I’m especially interested in the sudden drop in growth over 2007, leading up to SXSW. Why is that? Will it fall back to that level once the Austin shine wears off?
I’ve heard rumors that they were forced to block an entire country, which was abusing the SMS features and costing Twitter tons of money. That might explain the sudden dropoff.
Thx a lot for the graphs. You do your research thoroughly.
Thanks for the twitter background info and the indexing lesson.
oh nice site dude,
i need some ideas like that!
It would be cool to see how this lines up with big stories about twitter, like John Edward’s twitter account annoucement.
This is the first time I’ve heard of twitter. It’s actually fairly addicting once you get in and start reading the posts.
Do you feel that the novelty will wear off after a few months (July / August)? Or, is this a mobile app that will help drive the development of more user generated content?
Thanks for the post…nice stats work. I’m curious to see how things go after the sxsw peak wears off. Long tail or not.
“Human Giant using Twitter at the MTV Movie Awards”
Aziz also mentioned Twitter at the Sasquatch music festival where he hosted the main stage on the second day (sans the rest of the Human Giant people or MTV for that matter).
Very informative data. Long tail at work indeed.
I see these results are dated with the year 2007. Now that Twitter has even more popularity that is still rapidly increasing, I wonder what way the charts would look in 2012.