One of the biggest frustrations of text-to-image generation AI models is that they feel like a black box. We know they were trained on images pulled from the web, but which ones? As an artist or photographer, an obvious question is whether your work was used to train the AI model, but this is surprisingly hard to answer.
Sometimes, the data isn’t available at all: OpenAI has said it’s trained DALL-E 2 on hundreds of millions of captioned images, but hasn’t released the proprietary data. By contrast, the team behind Stable Diffusion have been very transparent about how their model is trained. Since it was released publicly last week, Stable Diffusion has exploded in popularity, in large part because of its free and permissive licensing, already incorporated into the new Midjourney beta, NightCafe, and Stability AI’s own DreamStudio app, as well as for use on your own computer.
But Stable Diffusion’s training datasets are impossible for most people to download, let alone search, with metadata for millions (or billions!) of images stored in obscure file formats in large multipart archives.
So, with the help of my friend Simon Willison, we grabbed the data for over 12 million images used to train Stable Diffusion, and used his Datasette project to make a data browser for you to explore and search it yourself. Note that this is only a small subset of the total training data: about 2% of the 600 million images used to train the most recent three checkpoints, and only 0.5% of the 2.3 billion images that it was first trained on.
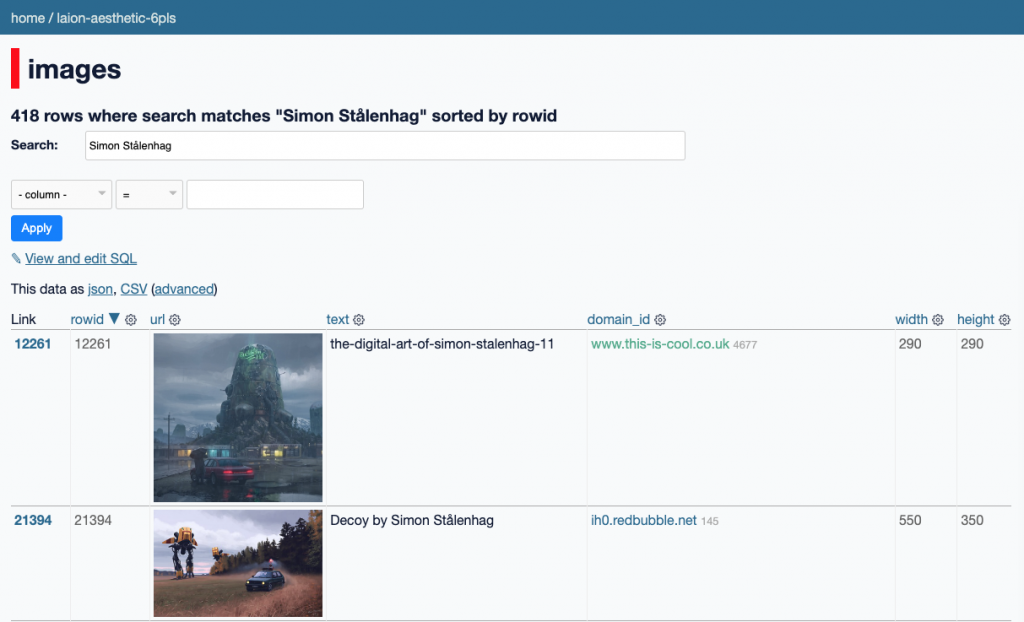
Go try it right now at laion-aesthetic.datasette.io! (Update: It’s now offline. See below for details.)
Read on to learn about how this dataset was collected, the websites it most frequently pulled images from, and the artists, famous faces, and fictional characters most frequently found in the data.
Data Source
Stable Diffusion was trained off three massive datasets collected by LAION, a nonprofit whose compute time was largely funded by Stable Diffusion’s owner, Stability AI.
All of LAION’s image datasets are built off of Common Crawl, a nonprofit that scrapes billions of webpages monthly and releases them as massive datasets. LAION collected all HTML image tags that had alt-text attributes, classified the resulting 5 billion image-pairs based on their language, and then filtered the results into separate datasets using their resolution, a predicted likelihood of having a watermark, and their predicted “aesthetic” score (i.e. subjective visual quality).

Stable Diffusion’s initial training was on low-resolution 256×256 images from LAION-2B-EN, a set of 2.3 billion English-captioned images from LAION-5B‘s full collection of 5.85 billion image-text pairs, as well as LAION-High-Resolution, another subset of LAION-5B with 170 million images greater than 1024×1024 resolution (downsampled to 512×512).
Its last three checkpoints were on LAION-Aesthetics v2 5+, a 600 million image subset of LAION-2B-EN with a predicted aesthetics score of 5 or higher, with low-resolution and likely watermarked images filtered out.
For our data explorer, we originally wanted to show the full dataset, but it’s a challenge to host a 600 million record database in an affordable, performant way. So we decided to use the smaller LAION-Aesthetics v2 6+, which includes 12 million image-text pairs with a predicted aesthetic score of 6 or higher, instead of the 600 million rated 5 or higher used in Stable Diffusion’s training.
This should be a representative sample of images used to train Stable Diffusion’s last three checkpoints, but skewing towards more aesthetically-attractive images. Note that LAION provides a useful frontend to search the CLIP embeddings computed from their 400M and 5 billion image datasets, but it doesn’t allow you to search the original captions.
Source Domains
We know the captioned images used for Stable Diffusion were scraped from the web, but from where? We indexed the 12 million images in our sample by domain to find out.
Nearly half of the images, about 47%, were sourced from only 100 domains, with the largest number of images coming from Pinterest. Over a million images, or 8.5% of the total dataset, are scraped from Pinterest’s pinimg.com CDN.
User-generated content platforms were a huge source for the image data. WordPress-hosted blogs on wp.com and wordpress.com represented 819k images together, or 6.8% of all images. Other photo, art, and blogging sites included 232k images from Smugmug, 146k from Blogspot, 121k images were from Flickr, 67k images from DeviantArt, 74k from Wikimedia, 48k from 500px, and 28k from Tumblr.
Shopping sites were well-represented. The second-biggest domain was Fine Art America, which sells art prints and posters, with 698k images (5.8%) in the dataset. 244k images came from Shopify, 189k each from Wix and Squarespace, 90k from Redbubble, and just over 47k from Etsy.
Unsurprisingly, a large number came from stock image sites. 123RF was the biggest with 497k, 171k images came from Adobe Stock’s CDN at ftcdn.net, 117k from PhotoShelter, 35k images from Dreamstime, 23k from iStockPhoto, 22k from Depositphotos, 22k from Unsplash, 15k from Getty Images, 10k from VectorStock, and 10k from Shutterstock, among many others.
It’s worth noting, however, that domains alone may not represent the actual sources of these images. For instance, there are only 6,292 images sourced from Artstation.com’s domain, but another 2,740 images with “artstation” in the caption text hosted by sites like Pinterest.
Artists
We wanted to understand how artists were represented in the dataset, so used the list of over 1,800 artists in MisterRuffian’s Latent Artist & Modifier Encyclopedia to search the dataset and count the number of images that reference each artist’s name. You can browse and search those artist counts here, or try searching for any artist in the images table. (Searching with quoted strings is recommended.)
Of the top 25 artists in the dataset, only three are still living: Phil Koch, Erin Hanson, and Steve Henderson. The most frequent artist in the dataset? The Painter of Light™ himself, Thomas Kinkade, with 9,268 images.
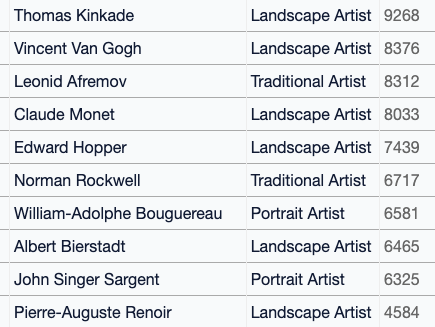
Using the “type” field in the database, you can see the most frequently-found artists in each category: for example, looking only at comic book artists, Stan Lee’s name is found most often in the image captions. (As one commenter pointed out, Stan Lee was a comic book writer, not an artist, but people are using his name to generate images in the style of comic book art he was associated with.)
Some of the most-cited recommended artists used in AI image prompting aren’t as pervasive in the dataset as you’d expect. There are only 15 images that mention fantasy artist Greg Rutkowski, whose name is frequently used as a prompt modifier, and only 73 from James Gurney.
(It’s worth saying again that these images are just a subset of one of three datasets used to train the AI, so an artist’s work may have been used elsewhere in the data even if they’re not found in these 12M images.)
Famous People
Unlike DALL-E 2, Stable Diffusion doesn’t have any limitations on generating images of people named in the dataset. To get a sense of how well-represented well-known people are in the dataset, we took two lists of celebrities and other famous names and merged it into a list of nearly 2,000 names. You can see the results of those celebrity counts here, or search for any name in the images table. (Obviously, some of the top searches like “Pink” and “Prince” include results that don’t refer to that person.)
Donald Trump is one of the most cited names in the image dataset, with nearly 11,000 photos referencing his name. Charlize Theron is a close runner-up with 9,576 images.


A full gender breakdown would take more time, but at a glance, it seems like many of the most popular names in the dataset are women.
Strangely, enormously popular internet personalities like David Dobrik, Addison Rae, Charli D’Amelio, Dixie D’Amelio, and MrBeast don’t appear in the captions from the dataset at all. My hunch was that the CommonCrawl data was too old to include these more recent celebrities, but based on the URLs, there are tens of thousands of images from last year in the data. (If you can solve this mystery, get in touch or leave a comment!)
Fictional Characters
Finally, we took a look at how popular fictional characters are represented in the dataset, since this is subject matter that’s enormously popular using Stable Diffusion and Craiyon, but often impossible with DALL-E 2, as you can see in this Mickey Mouse example from my previous post.


For this set of searches, we used this list of 600 fictional characters from pop culture to search the image dataset. You can browse the results here, or search for any other character in the images table. (Again, be aware that one-word character names like “Link,” “Data,” and “Mario” are likely to have many more results unrelated to that character.)
Characters from the MCU like Captain Marvel (4,993 images), Black Panther (4,395), and Captain America (3,155) are some of the best represented in the dataset. Batman (2,950) and Superman (2,739) are neck and neck. Luke Skywalker (2,240) has more images than Darth Vader (1.717) and Han Solo (1,013). Mickey Mouse barely breaks the top 100 with 520 images.
NSFW Content
Finally, let’s take a brief look at the representation of adult material, another huge difference between Stable Diffusion and any other model. OpenAI rigorously removed sexual/violent content from its training data and blocked potentially NSFW keywords from prompts.
The Stable Diffusion team built a predictor for adult material and assigned every image a NSFW probability score, which you can see in the “punsafe” field in the images table, ranging from 0 to 1. (Warning: Obviously, sorting by that field will show the most NSFW images in the dataset.)
In their announcements of the full LAION-5B dataset, LAION team member Romain Beaumont estimated that about 2.9% of the English-language images were “unsafe,” but in browsing this dataset, it’s not clear how their predictors defined that.
There’s definitely NSFW material in the image dataset, but surprisingly little of it. Only 222 images got a “1” unsafe probability score, indicating 100% confidence that it’s unsafe, about 0.002% of the total images — and those are definitely porn. But nudity seems to be unusual outside of that confidence level: even images with a 0.9999 punsafe score (99.99% confidence) rarely have nudity in them.
It’s plausible that filtering on aesthetic ratings is removing huge amounts of NSFW content from the image dataset, and the full dataset contains much more. Or maybe their definitions of what is “unsafe” are very broad.
More Info
Again, huge thanks to Simon Willison for working with me on this: he did all the heavy lifting of hosting the data. He wrote a detailed post about making the search engine if you want more technical detail. His Datasette project is open-source, extremely flexible, and worth checking out. If you’re interested in playing with this data yourself, you can use the scripts in his GitHub repo to download and import it into a SQLite database.
If you find anything interesting in the data, or have any questions, feel free to drop them in the comments.
Update
On December 20, 2023, LAION took down its LAION-5B and LAION-400M datasets after a new study published by the Stanford Internet Observatory found that it included links to child sexual abuse material. As reported by 404 Media, “The LAION-5B machine learning dataset used by Stable Diffusion and other major AI products has been removed by the organization that created it after a Stanford study found that it contained 3,226 suspected instances of child sexual abuse material, 1,008 of which were externally validated.”
The subset of “aesthetic” images we analyzed was only 2% of the full 2.3 billion image dataset, and of those 12 million images, only 222 images were classified as NSFW. As a result, it’s unlikely any of those links go to CSAM imagery, but because it’s impossible to know with certainty, Simon took the precaution of permanently shuttering the LAION-Aesthetic browser.
As Simon Willison wrote, the LAION dataset is composed of images collected without the permission of their originators. I’m curious whether this would open up Stable Diffusion’s creations to accusations of being the fruits of a poisonous tree.
Yes clearly the LAION team is not picky about only looking for images under Creative Commons. It will be interesting to see what happens when Stable Diffusion has copyright holders come knocking on their door.
That said, many Creative Commons-licensed images require attribution and non-commercial use. It’s an open question whether this is a fair use of those images and can ignore those requirements.
Stan Lee, Alan Moore, Warren Ellis, and other comic book artists listed did all or almost all of their work in writing scripts, not the visual output. I’m curious what using their names for terms would result in – a mishmash of the styles of the artists that they’ve worked with?
That sounds about right. You can see some examples in the Stan Lee, Alan Moore, and Warren Ellis searches on Lexica.
People put some rather questionable keyword spam in alt image text it seems. I tried looking for art by Theodor Kittelsen, a 19th century Norwegian illustrator and painter, known for a mix of national romanticism and his whimsical, somewhat grotesque pictures of trolls and anthropomorphic animals. I spotted the keyword “aryan” on some of his pictures.
The LAION researchers attempted to filter out alt-text captions that didn’t match the image by using OpenAI’s CLIP model to compute the image and text embeddings, calculate the cosine similarity between them, and drop the ones with the lowest similarity. Makes sense that wouldn’t be perfect.
So, I found 5 of my drawings on there. Is there a way to get them removed?
As far as I know, there’s no way to remove images from the training data or to get the model to unlearn what it’s learned from them.
LAION has a GDPR link for EU citizens. You can remove it that way.
True, but removing your data from the LAION dataset won’t remove it from any of the models that were already trained with it.
Is this model being updated? Is there a way to add images to the dataset manually, ţo give the AI better information on say, anatomy, which they really struggle to grasp?
The model weights are continuing to be updated: their new 1.5 checkpoint should be released any day now, it’s already deployed on Dreamstudio, their commercial app. You can fine-tune Stable Diffusion on concepts (i.e. people, objects, characters, art styles) it’s unfamiliar with using a technique called textual inversion with 3-5 example images. There’s a growing concepts library, where people are sharing their newly-trained concepts.
A quick search through the punsafe=1 images reveals that most of them are poor quality thumbnails, with very limited poses (almost none of intercourse), chiefly caucasian performers, and there are so many duplicates the same images (eg. 76 of the 222 images were the very same “Skilled masseur India Summer knows how to make her client fully satisfied”). Perhaps the AI is sophisticated enough to compensate for a lack of quality or diverse subjects, but it shows a distinct bias in the dataset – I have to wonder if it was intentionally curated this way?
Like I mentioned in the post, my assumption is that the Aesthetic 6+ subset that we looked at likely cut out a huge number of unsafe images from the 400M Aesthetic 5+ dataset, as well as the massive 2.3B image crawl. I don’t believe there was any editorial curation happening, it’s just an artifact of the contents of the Common Crawl source data and their attempts to filter out predicted non-“aesthetic” and watermarked images.
Are these used to train the CLIP text encoder, or the diffusion model part, or both? (Excuse my ignorance, I’m a student just learning.)
The diffusion model. The original Stable Diffusion was OpenAI’s CLIP, and we don’t know what they used to train it.
LAION’s projects in Github include a watermark detection tool. From your work, do you believe that is to eliminate images from a dataset or to remove the watermark before the image is subject to diffusion training? In other words, is the diffusion trained to “look behind” or ignore a watermark in its pixel level analysis or are watermarked pictures omitted from the dataset. (I do not mean the term “watermark” to indicate a mark in the metadata that is embedded in neural networks or AI generated images, but the old fashioned watermark that is visually noticeable on an image.)
No, they don’t attempt to remove watermarks from images. Anything with a predicted watermark score of 0.8 is filtered out from the training dataset.
Thanks for an insightful read. I notice within even this subset there are many duplicate (and triplicate….) images – is there any de-duplication before training? – it would seem a relatively straightforward task.
The version of the Stable Diffusion training data we looked at wasn’t deduped, as far as I can tell. OpenAI wrote about some of the challenges in deduping hundreds of millions of images for DALL-E 2, and how they handled it.
Thank you for such an ambitious project ! I was wondering how you were able to showcase these copyrighted images on a website ? Is it legal to show the images of a dataset without the permission of the copyright holders ?
Every image on the data browser is linked directly from the server that’s hosting it, using the URL found in the training data set. We’re not storing or serving copies of any images.
Hi! I’m noticing that the browser is unavailable as of right now. Is the link broken, or has it moved somewhere else?
It’s down permanently. See the update at the end of my post.