Leonardo DiCaprio Refuses to Date a Woman Over 25
— updated for 2022, a very good chart made in Excel/Powerpoint #
Perfect Tides, a Coming-of-Age Point-and-Click Adventure, Kickstarts a Sequel
There’s no shortage of amazing games so far this year, but my personal favorite is an underdog: Perfect Tides, a ’90s-esque point-and-click adventure about growing up as a teen on a sleepy island resort town in the early 2000s, finding an escape from real-life feelings of loneliness and loss in discussion forums and late-night AIM chats.

The first game from Meredith Gran, creator of the decade-long comic series Octopus Pie, it approaches challenging subjects with the confidence of someone who created narrative comics every week for ten years. I can’t think of another comics artist who has dived into game design like this, but it pays off with uniquely charming pixel art and animation, colorful writing, and a story that genuinely moved me by the end. It navigates complex feelings about family, old friends, and new loves, while also being genuinely funny.
Let’s put it this way: I’ve been playing videogames for the last 35 years, but Perfect Tides is the first time I felt compelled to write a walkthrough (spoilers!) and actively participate in forums to help people finish it.
This is a long way of saying that you should play Perfect Tides on Steam or Itch, and then go back the Kickstarter for its sequel, Perfect Tides: Station to Station, which has only six days to go and still needs another $20,000 to cross the finish line. (Update: It hit the goal!)
But you don’t have to take my word for it! Kotaku said the original game was “one of the year’s best,” the “kind of game you don’t even see coming, yet turns out to be incredible” and “perfectly captures the intensity and struggle of adolescence.” AV Club called it a “harrowing, funny, beautiful, horrifying, and ultimately reassuring work of art.” Polygon summed it up as “devastatingly honest.” My favorite review was from Buried Treasure’s John Walker, who wrote, “It is the most extraordinary exploration of what it is to be a teenager, told with such heart, such truth.”
Spoilers Ahoy
If you’ve already played Perfect Tides, I want to mention two key moments that are so wonderful, and yet so easy to miss in your first playthrough, they’re worth replaying it for. THESE ARE SPOILERS!
First, if you didn’t manage to patch things up with Lily, you missed a long sequence with her in the final season of the game. (To get the full experience of that sequence, you’ll need to find a specific MP3 and put into the game directory when prompted: a remarkable breaking-the-fourth-wall sidestep around copyright licensing that I’ve never seen in a game before.)
Second, there are two major endings. If it feels anticlimactic, you likely didn’t resolve your conflicts with Lily, Simon, and your family. There are 95 possible points, but you don’t need them all to get the best ending. Feel free to use my 100% completion guide for help getting there.
Perfect Tides isn’t perfect. Like any classic point-and-click adventure, there are some clunky bits here and there, and you’ll likely need the occasional hint or glance at a playthrough to finish. But it’s so worth it.

Know Your Meme’s analysis of meme origins by platform from 2010-2022
— TikTok is now fully half of new memes tracked on the site #
Retrospective of Medium’s first ten years
— curious to see where it goes next under its new CEO, Tony Stubblebine (via) #
How Twitter’s child porn problem ruined its plans for an OnlyFans competitor
— scoop from Zoe Schiffer and Casey Newton; Elon Musk's buyout attempt shifted their focus to spam bots #
The Big [Censored] Theory
— Manyun Zou digs into Chinese censorship of the Big Bang Theory for The Pudding #
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator
One of the biggest frustrations of text-to-image generation AI models is that they feel like a black box. We know they were trained on images pulled from the web, but which ones? As an artist or photographer, an obvious question is whether your work was used to train the AI model, but this is surprisingly hard to answer.
Sometimes, the data isn’t available at all: OpenAI has said it’s trained DALL-E 2 on hundreds of millions of captioned images, but hasn’t released the proprietary data. By contrast, the team behind Stable Diffusion have been very transparent about how their model is trained. Since it was released publicly last week, Stable Diffusion has exploded in popularity, in large part because of its free and permissive licensing, already incorporated into the new Midjourney beta, NightCafe, and Stability AI’s own DreamStudio app, as well as for use on your own computer.
But Stable Diffusion’s training datasets are impossible for most people to download, let alone search, with metadata for millions (or billions!) of images stored in obscure file formats in large multipart archives.
So, with the help of my friend Simon Willison, we grabbed the data for over 12 million images used to train Stable Diffusion, and used his Datasette project to make a data browser for you to explore and search it yourself. Note that this is only a small subset of the total training data: about 2% of the 600 million images used to train the most recent three checkpoints, and only 0.5% of the 2.3 billion images that it was first trained on.
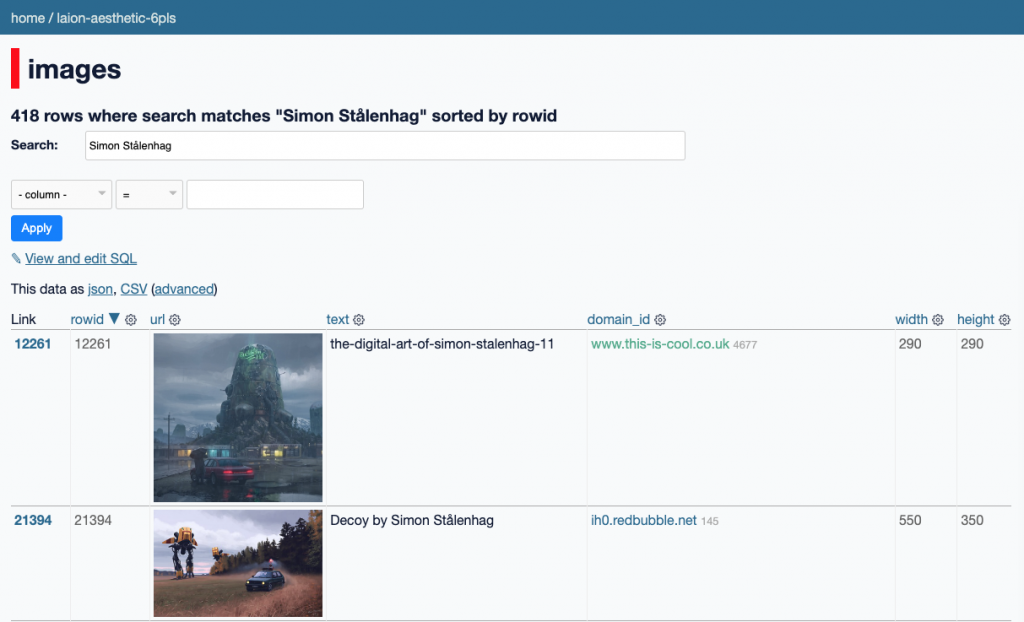
Go try it right now at laion-aesthetic.datasette.io! (Update: It’s now offline. See below for details.)
Read on to learn about how this dataset was collected, the websites it most frequently pulled images from, and the artists, famous faces, and fictional characters most frequently found in the data.
Data Source
Stable Diffusion was trained off three massive datasets collected by LAION, a nonprofit whose compute time was largely funded by Stable Diffusion’s owner, Stability AI.
All of LAION’s image datasets are built off of Common Crawl, a nonprofit that scrapes billions of webpages monthly and releases them as massive datasets. LAION collected all HTML image tags that had alt-text attributes, classified the resulting 5 billion image-pairs based on their language, and then filtered the results into separate datasets using their resolution, a predicted likelihood of having a watermark, and their predicted “aesthetic” score (i.e. subjective visual quality).

Stable Diffusion’s initial training was on low-resolution 256×256 images from LAION-2B-EN, a set of 2.3 billion English-captioned images from LAION-5B‘s full collection of 5.85 billion image-text pairs, as well as LAION-High-Resolution, another subset of LAION-5B with 170 million images greater than 1024×1024 resolution (downsampled to 512×512).
Its last three checkpoints were on LAION-Aesthetics v2 5+, a 600 million image subset of LAION-2B-EN with a predicted aesthetics score of 5 or higher, with low-resolution and likely watermarked images filtered out.
For our data explorer, we originally wanted to show the full dataset, but it’s a challenge to host a 600 million record database in an affordable, performant way. So we decided to use the smaller LAION-Aesthetics v2 6+, which includes 12 million image-text pairs with a predicted aesthetic score of 6 or higher, instead of the 600 million rated 5 or higher used in Stable Diffusion’s training.
This should be a representative sample of images used to train Stable Diffusion’s last three checkpoints, but skewing towards more aesthetically-attractive images. Note that LAION provides a useful frontend to search the CLIP embeddings computed from their 400M and 5 billion image datasets, but it doesn’t allow you to search the original captions.
Source Domains
We know the captioned images used for Stable Diffusion were scraped from the web, but from where? We indexed the 12 million images in our sample by domain to find out.
Nearly half of the images, about 47%, were sourced from only 100 domains, with the largest number of images coming from Pinterest. Over a million images, or 8.5% of the total dataset, are scraped from Pinterest’s pinimg.com CDN.
User-generated content platforms were a huge source for the image data. WordPress-hosted blogs on wp.com and wordpress.com represented 819k images together, or 6.8% of all images. Other photo, art, and blogging sites included 232k images from Smugmug, 146k from Blogspot, 121k images were from Flickr, 67k images from DeviantArt, 74k from Wikimedia, 48k from 500px, and 28k from Tumblr.
Shopping sites were well-represented. The second-biggest domain was Fine Art America, which sells art prints and posters, with 698k images (5.8%) in the dataset. 244k images came from Shopify, 189k each from Wix and Squarespace, 90k from Redbubble, and just over 47k from Etsy.
Unsurprisingly, a large number came from stock image sites. 123RF was the biggest with 497k, 171k images came from Adobe Stock’s CDN at ftcdn.net, 117k from PhotoShelter, 35k images from Dreamstime, 23k from iStockPhoto, 22k from Depositphotos, 22k from Unsplash, 15k from Getty Images, 10k from VectorStock, and 10k from Shutterstock, among many others.
It’s worth noting, however, that domains alone may not represent the actual sources of these images. For instance, there are only 6,292 images sourced from Artstation.com’s domain, but another 2,740 images with “artstation” in the caption text hosted by sites like Pinterest.
Artists
We wanted to understand how artists were represented in the dataset, so used the list of over 1,800 artists in MisterRuffian’s Latent Artist & Modifier Encyclopedia to search the dataset and count the number of images that reference each artist’s name. You can browse and search those artist counts here, or try searching for any artist in the images table. (Searching with quoted strings is recommended.)
Of the top 25 artists in the dataset, only three are still living: Phil Koch, Erin Hanson, and Steve Henderson. The most frequent artist in the dataset? The Painter of Light™ himself, Thomas Kinkade, with 9,268 images.
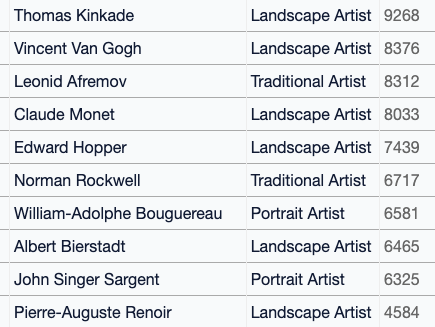
Using the “type” field in the database, you can see the most frequently-found artists in each category: for example, looking only at comic book artists, Stan Lee’s name is found most often in the image captions. (As one commenter pointed out, Stan Lee was a comic book writer, not an artist, but people are using his name to generate images in the style of comic book art he was associated with.)
Some of the most-cited recommended artists used in AI image prompting aren’t as pervasive in the dataset as you’d expect. There are only 15 images that mention fantasy artist Greg Rutkowski, whose name is frequently used as a prompt modifier, and only 73 from James Gurney.
(It’s worth saying again that these images are just a subset of one of three datasets used to train the AI, so an artist’s work may have been used elsewhere in the data even if they’re not found in these 12M images.)
Famous People
Unlike DALL-E 2, Stable Diffusion doesn’t have any limitations on generating images of people named in the dataset. To get a sense of how well-represented well-known people are in the dataset, we took two lists of celebrities and other famous names and merged it into a list of nearly 2,000 names. You can see the results of those celebrity counts here, or search for any name in the images table. (Obviously, some of the top searches like “Pink” and “Prince” include results that don’t refer to that person.)
Donald Trump is one of the most cited names in the image dataset, with nearly 11,000 photos referencing his name. Charlize Theron is a close runner-up with 9,576 images.


A full gender breakdown would take more time, but at a glance, it seems like many of the most popular names in the dataset are women.
Strangely, enormously popular internet personalities like David Dobrik, Addison Rae, Charli D’Amelio, Dixie D’Amelio, and MrBeast don’t appear in the captions from the dataset at all. My hunch was that the CommonCrawl data was too old to include these more recent celebrities, but based on the URLs, there are tens of thousands of images from last year in the data. (If you can solve this mystery, get in touch or leave a comment!)
Fictional Characters
Finally, we took a look at how popular fictional characters are represented in the dataset, since this is subject matter that’s enormously popular using Stable Diffusion and Craiyon, but often impossible with DALL-E 2, as you can see in this Mickey Mouse example from my previous post.


For this set of searches, we used this list of 600 fictional characters from pop culture to search the image dataset. You can browse the results here, or search for any other character in the images table. (Again, be aware that one-word character names like “Link,” “Data,” and “Mario” are likely to have many more results unrelated to that character.)
Characters from the MCU like Captain Marvel (4,993 images), Black Panther (4,395), and Captain America (3,155) are some of the best represented in the dataset. Batman (2,950) and Superman (2,739) are neck and neck. Luke Skywalker (2,240) has more images than Darth Vader (1.717) and Han Solo (1,013). Mickey Mouse barely breaks the top 100 with 520 images.
NSFW Content
Finally, let’s take a brief look at the representation of adult material, another huge difference between Stable Diffusion and any other model. OpenAI rigorously removed sexual/violent content from its training data and blocked potentially NSFW keywords from prompts.
The Stable Diffusion team built a predictor for adult material and assigned every image a NSFW probability score, which you can see in the “punsafe” field in the images table, ranging from 0 to 1. (Warning: Obviously, sorting by that field will show the most NSFW images in the dataset.)
In their announcements of the full LAION-5B dataset, LAION team member Romain Beaumont estimated that about 2.9% of the English-language images were “unsafe,” but in browsing this dataset, it’s not clear how their predictors defined that.
There’s definitely NSFW material in the image dataset, but surprisingly little of it. Only 222 images got a “1” unsafe probability score, indicating 100% confidence that it’s unsafe, about 0.002% of the total images — and those are definitely porn. But nudity seems to be unusual outside of that confidence level: even images with a 0.9999 punsafe score (99.99% confidence) rarely have nudity in them.
It’s plausible that filtering on aesthetic ratings is removing huge amounts of NSFW content from the image dataset, and the full dataset contains much more. Or maybe their definitions of what is “unsafe” are very broad.
More Info
Again, huge thanks to Simon Willison for working with me on this: he did all the heavy lifting of hosting the data. He wrote a detailed post about making the search engine if you want more technical detail. His Datasette project is open-source, extremely flexible, and worth checking out. If you’re interested in playing with this data yourself, you can use the scripts in his GitHub repo to download and import it into a SQLite database.
If you find anything interesting in the data, or have any questions, feel free to drop them in the comments.
Update
On December 20, 2023, LAION took down its LAION-5B and LAION-400M datasets after a new study published by the Stanford Internet Observatory found that it included links to child sexual abuse material. As reported by 404 Media, “The LAION-5B machine learning dataset used by Stable Diffusion and other major AI products has been removed by the organization that created it after a Stanford study found that it contained 3,226 suspected instances of child sexual abuse material, 1,008 of which were externally validated.”
The subset of “aesthetic” images we analyzed was only 2% of the full 2.3 billion image dataset, and of those 12 million images, only 222 images were classified as NSFW. As a result, it’s unlikely any of those links go to CSAM imagery, but because it’s impossible to know with certainty, Simon took the precaution of permanently shuttering the LAION-Aesthetic browser.
Opening the Pandora’s Box of AI Art
Last month, I finally got access to OpenAI’s DALL·E 2 and immediately started exploring the text-to-image AI’s potential for creative shitposting, generating horror after horror: the Eames Lounge Toilet, the Combination Pizza Hut and Frank Lloyd Wright’s Fallingwater, toddler barflies, Albert Einstein inventing jorts, and the can’t-unsee “close up photo of brushing teeth with toothbrush covered with nacho cheese.”



DALL·E 2 diligently hallucinated each image out of noise from the compressed latent space, multi-dimensional patterns discovered in hundreds of millions of captioned images scraped from the internet.


The prompt that finally melted my brain was the one above, with images of slugs getting married at golden hour. I originally specified a “tuxedo and wedding dress” with predictable results, but changing it to “wedding attire” gave the AI the flexibility to depict variations of what slugs might marry in, like headdresses made of cotton balls and honeycomb.
I’ve never felt so conflicted using an emerging technology as DALL·E 2, which feels like borderline magic in what it’s capable of conjuring, but raises so many ethical questions, it’s hard to keep track of them all.
There are the many known issues that OpenAI’s acknowledged and worked to mitigate, like racial or gender biases in its image training set, or the lengths they’ve gone to avoid generating sexual/violent content or recognizable celebrities and trademarked characters.
But it opens profound questions about the ethics of laundering human creativity:
- Is it ethical to train an AI on a huge corpus of copyrighted creative work, without permission or attribution?
- Is it ethical to allow people to generate new work in the styles of the photographers, illustrators, and designers without compensating them?
- Is it ethical to charge money for that service, built on the work of others?
There are basic fundamental questions about whether it’s even legal: these are largely untested waters in copyright law and it seems destined to end up in court. Training deep learning models on copyrighted material may be fair use, but only a judge can decide that. (The fact that OpenAI’s removing some results from the image training set, like celebrity faces and Disney/Marvel characters, suggests they’re well aware of angering the biggest litigants.)

As these models improve, it seems likely to reduce demand in some paid creative services, from stock photography to commissioned illustrations. I empathize with the concerns of artists whose work was silently used to train commercial products in their style, without their consent and with no way to opt-out.
The world was just starting to grapple with the implications of this technology when, on Monday, a company called Stability AI released its Stable Diffusion text-to-image AI publicly.
Stable Diffusion is free, open-source, runs on your own computer, and ships without any of the guardrails and content filters of its predecessors. It comes with a Safety Classifier enabled by default that tries to determine if a generated image is NSFW, but it’s easily disabled.



Unlike existing AI platforms like DALL·E 2 and Midjourney, Stable Diffusion can generate recognizable celebrities, nudity, trademarked characters, or any combination of those. (Try searching Lexica, the newly-launched Stable Diffusion search engine, for example output.)
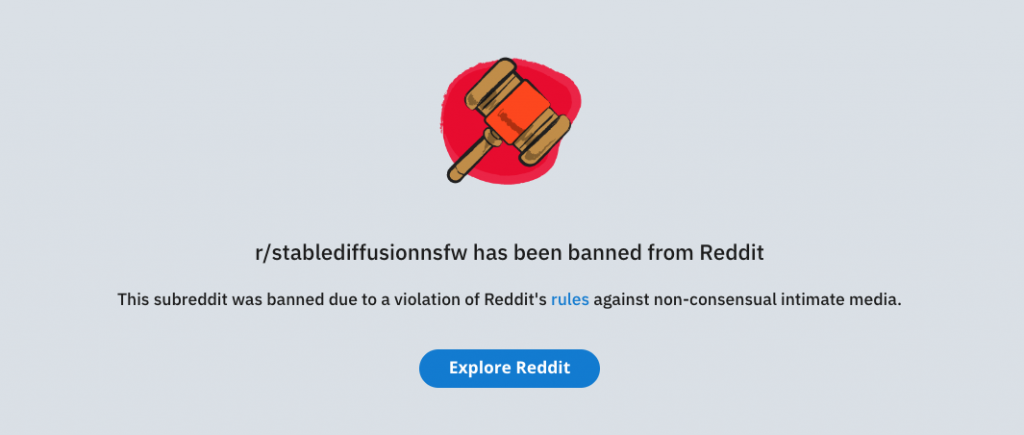
Releasing an uncensored dream machine into the wild had some predictable results. Two days after its release, Reddit banned three subreddits devoted to NSFW imagery made with Stable Diffusion, presumably because of the rapid influx of AI-generated fake nudes of Emma Watson, Selena Gomez, and many others.
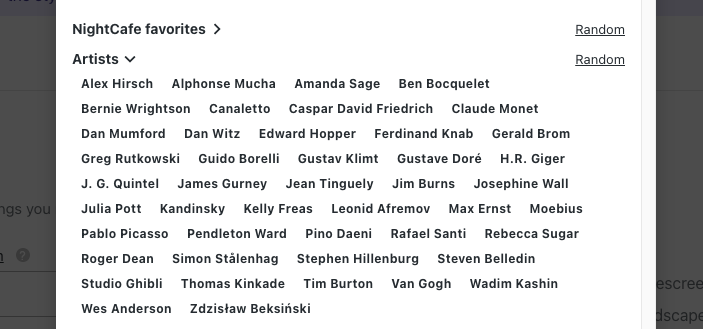
The permissive license on Stable Diffusion allows commercial services to implement its AI model, such as NightCafe, which encourages paying customers to generate art in the styles of living artists like Pendleton Ward, Greg Rutkowski, Amanda Sage, Rebecca Sugar, and Simon Stålenhag, who has spoken out against the practice.
On top of it, Stable Diffusion’s terms state that every image generated with their Dream Studio is effectively public domain, under the CC0 1.0 Public Domain license. They make no claim over the copyright of images generated with the self-hosted Stable Diffusion model. (OpenAI’s terms says that images created with DALL·E 2 are their property, with customers granted a license to use them commercially.)
A common argument I’ve seen is that training AI models is like an artist learning to paint and finding inspiration by looking at other artwork, which feels completely absurd to me. AI models are memorizing the features found in hundreds of millions of images, and producing images on demand at a scale unimaginable for any human—thousands every minute.
The results can be surprising and funny and beautiful, but only because of the vast trove of human creativity it was trained on. Stable Diffusion was trained on LAION-Aesthetic, a 120-million image subset of a 5 billion image crawl of image-text pairs from the web, winnowed down to the most aesthetically attractive images. (OpenAI has been more cagey about its sources.)
There’s no question it takes incredible engineering skill to develop systems to analyze that corpus and generate new images from it, but if any of these systems required permission from artists to use their images, they likely wouldn’t exist.
Stability AI founder Emad Mostaque believes the good of new technology will outweigh the harm. “Humanity is horrible and they use technology in horrible ways, and good ways as well,” Mostaque said in an interview two weeks ago. “I think the benefits far outweigh any negativity and the reality is that people need to get used to these models, because they’re coming one way or another.” He thinks that OpenAI’s attempts to minimize bias and mitigate harm are “paternalistic,” and a sign of distrust of their userbase.
Today we all made the World a more creative, happier and communicative place.
— Emad (@EMostaque) August 22, 2022
More to come in the next few days but I for one can’t wait to see what you all create.
Let’s activate humanity’s potential.
In that interview, Mostaque says that Stability AI and LAION were largely self-funded from his career as a hedge fund manager, and with additional resources, they’ve created a 4,000 A100 cluster with the support of Amazon that “ranks above JUWELS Booster as potentially the tenth fastest supercomputer.”
On Monday, Mostaque wrote that they plan to use those compute resources to expand to other AI-generated media: audio next month, and then 3D and video. I’d expect Stability AI to approach these new models in the same way, with little concern over their potential for misuse by bad actors, and with even less attention spent addressing the concerns of the artists and creators whose work makes them possible.
Like I said, I’m conflicted. I love playing with new technology, and I’m excited about the creative potential of these new tools. I want to feel good about the tools I use.
I don’t trust OpenAI for a bunch of reasons, but at least they seemed to try to do the right thing with their various efforts to reduce bias and potential harm, even if it’s sometimes clumsy.
Stable Diffusion’s approach feels irresponsible by comparison, another example of techno-utopianism unmoored from the reality of the internet’s last 20 years: how an unwavering commitment to ideals of free speech and anti-censorship can be deployed as a convenient excuse not to prevent abuse.
For now, generative AI platforms are some of the most resource-intensive projects in the world, leading to a vanishingly small number of participants with access to vast compute resources. It would be nice if those few companies would act responsibly by, at the very least, providing an opt-out for those who don’t want their work in future training data, finding new ways to help artists that do choose to participate, and following the lead of OpenAI in trying to minimize the potential for harm.
I don’t pretend to know where these things will go: the risks may be overblown and we may be at the start of a massive democratization in the creation of art, or these platforms may make the already-precarious lives of artists harder, while opening up new avenues for deepfakes, misinformation, and online harassment and exploitation. I’d really like to see more of the former, but it won’t happen on its own.
An Oral History of Tim Curry’s Escape to the One Place Uncorrupted by Capitalism
— among the interviewees, two NASA astronauts, an astrophysicist, and a former Greek Minister of Finance #
NYT profiles Michael Heizer’s “City”
— 50 years in the making, a massive 1.5 x 0.5 mile land art installation in the Nevada desert (via) #
Making an Internet Time Machine
— a Raspberry Pi-based plug-and-play box running Wayback Proxy to browse the old web on old computers #
New World Unlocked
— GLASYS drew pixel art frame-by-frame for the first single off his upcoming 8-bit album #
Stable Diffusion public release
— open-source text-to-image AI model that runs on your own GPU, similar quality as DALL-E 2 without content filters #
Profile of Stable Diffusion, the open-source text-to-image AI model without content filters and safeguards
— new Pandora's box just dropped #
John Deere tractors jailbroken at DefCon, allowing farmers to repair their own equipment
— and yes, this means you can play Doom on them #
How magicians made a fortune on Facebook
— the industry best suited to deceiving people for fun and profit; see Ryan Broderick's earlier reporting on Rick Lax and friends #
The Verge profiles Archive of Our Own for its 15th birthday
— interesting read on the origins of the fan-run fanfic community and its issues addressing racism #
The Biggest Deal in Climate History Almost Didn’t Happen
— Hank Green's excellent explainer on the details of the confusingly-named Inflation Reduction Act #
Life on the Internet
— charmingly naive 13-part TV series from 1996, captures footage of sites that predate the Internet Archive (via) #
Physically simulating an entire car engine for realistic audio
— it needs to run at 80,000 FPS to remain stable #
The Kubrick Times
— using GPT-3 and DALL-E 2 to make full articles for the future NYT headlines written in 1965 by Kubrick's team for 2001: A Space Odyssey #
Map of most notable people around the world
— using metadata from Wikipedia and Wikidata, including article length, views, and external links (via) #
Amazon’s third-party seller piracy problem
— Amazon gets paid either way, so they're unlikely to fix it #
The Apple Store Time Machine
— interactive macOS app with four meticulous reconstructions of Apple Stores on their opening days #
Molly White on victim-blaming in the crypto crash
— related: her excerpts from letters to the judges of the Celsius Network and Voyager Digital bankruptcy cases (via) #
Stray, tilt-shifted
— I finished the cat game this weekend and it was a pure joy, highly recommended #
Infinite Mac adds virtual networking
— you can now play games remotely with Mihai Parparita's full-featured in-browser classic 68K Mac #
Joni Mitchell performs first full set in over 20 years
— she spent years recovering from a 2015 brain aneurysm, relearning guitar by watching videos of herself playing #
Absurd AI-generated food photography with DALL-E 2
— Max Woolf serves up Rubik's Cube PB&Js and five-dimensional burgers #
The Secret History Of The Internet’s Funniest Buzzer-Beater
— Brian Feldman goes deep into a '90s viral video and tracks down everyone involved (via) #
Scratch, MIT Media Lab’s visual coding platform for kids, is blowing up
— it doubled in popularity in the last two years #
The Verge on how indie writers are using AI tools like Sudowrite and Jasper
— love the interactive article design #
Everyone Everywhere Needs Waymond Wang
— Pop Culture Detective on Everything Everywhere All At Once's subversive portrayal of masculinity #
Lego makes Atari 2600 set for Atari’s 50th anniversary
— from the fold-out 1980s living room to the game cartridge dioramas, this was laser-targeted to me #
RIP Sockington
— at his peak, Jason Scott's adorable cat had over 1.5M Twitter followers and was in the top 100 most-followed accounts #
Anil Dash talks about his violent assault at a California coffee shop
— "Our institutions have no capability for responding to crisis with compassion." #
Doom running inside Doom II
— Doom for DOS exploit lets you run Doom and Heretic as animated textures (via) #