Yesterday, Quora announced that 100 million user accounts were compromised, including private activity like downvotes and direct messages, by a “malicious third party.”
Data breaches are a frustrating part of the lifecycle of every online service — as they grow in popularity, they become a bigger and bigger target. Nearly every major online service has had a security breach: Facebook, Google, Twitter, Yahoo, Tumblr, Uber, Evernote, eBay, Adobe, Target, and Sony all extensively leaked user data in the last few years.
Security breaches like these are a strong argument for using a password manager, but not a compelling reason to avoid a service you love, unless you plan to quit the internet entirely.
But this does seem like a good time to remind you of all the other reasons why you should never, ever use Quora.
Hoarding Knowledge
Four years ago, Eric Mill wrote about Quora’s tendency to hoard knowledge, and nothing’s changed since.
According to their About page, “Quora’s mission is to share and grow the world’s knowledge.” With 300 million monthly users, and nearly 40 million questions asked so far, they’re doing a good job of growing the world’s knowledge, but a terrible job of sharing it.
All of Quora’s value is derived from the answers provided by its users, and they go to great lengths to make a well-designed platform for finding and replying to questions.
But they do everything they can to make sure you can’t get those contributions back out.
Quora has:
- No public API.
- No backup or export tools.
- Restricted access to answers without an account.
- Blocked scrapers and unofficial APIs, and deleted questions related to scraping on their site.
Contrast that with Q&A competitors Stack Overflow and Stack Exchange, which offers an API, a wealth of user-made tools and support community for it, a powerful Data Explorer for querying and exporting data, a liberal crawling policy, and doesn’t attempt to hide questions and answers behind authentication. They even proactively upload anonymized data dumps of all user-contributed content to the Internet Archive for posterity under a Creative Commons license.
Hell, even Ask MetaFilter lets you export your history, and that was mostly built by one person.
Blocking Preservation
If you want to be generous, you could argue that it’s not a priority for them to build features like an API or export tools, especially as they’re still struggling to make money.
But for years, Quora has also explicitly forbidden the Internet Archive from indexing their site. This is what you’ll see if you try to find any Quora page in the Wayback Machine’s index.
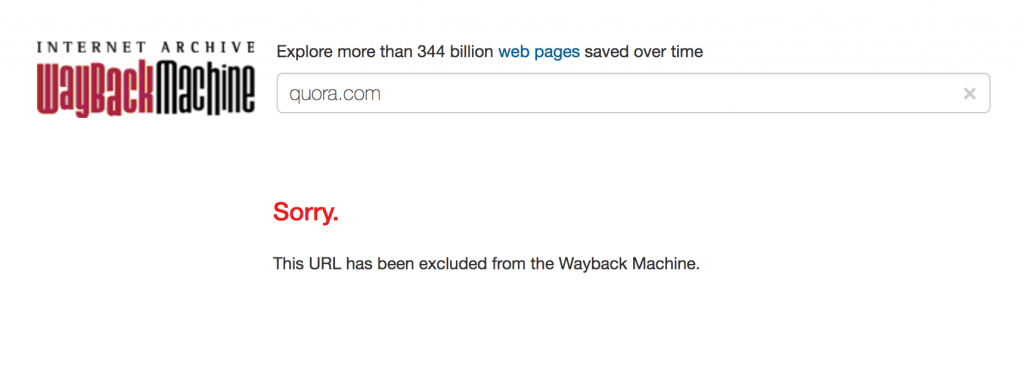
Quora could do literally nothing, and the Internet Archive would actively preserve the work of their millions of users for the future, but they’ve chosen to exclude their site from being archived.
In their robots.txt file, they elaborate on why they block the Wayback Machine, claiming they do it to protect their writers.
People share a lot of sensitive material on Quora – controversial political views, workplace gossip and compensation, and negative opinions held of companies. Over many years, as they change jobs or change their views, it is important that they can delete or anonymize their previously-written answers.
We opt out of the wayback machine because inclusion would allow people to discover the identity of authors who had written sensitive answers publicly and later had made them anonymous, and because it would prevent authors from being able to remove their content from the internet if they change their mind about publishing it. As far as we can tell, there is no way for sites to selectively programmatically remove content from the archive and so this is the only way for us to protect writers. If they open up an API where we can remove content from the archive when authors remove it from Quora, but leave the rest of the content archived, we would be happy to opt back in.
The Internet Archive is a historical archive of the public internet, and Quora asking for the ability to selectively modify their archives is absurd. An API like they’re suggesting would be ripe for abuse.
The Internet Archive inadvertently acts as a contingency for every startup’s short-sighted business plan, disastrous pivots, or acquisitions gone awry. When you run a social platform with content generated by the community, you have a larger responsibility not to burn their collective work to the ground. Part of that responsibility is participating in the web, and giving back what you take from it.
From the Wayback Machine’s FAQ:
Why is the Internet Archive collecting sites from the Internet? What makes the information useful?
Most societies place importance on preserving artifacts of their culture and heritage. Without such artifacts, civilization has no memory and no mechanism to learn from its successes and failures. Our culture now produces more and more artifacts in digital form. The Archive’s mission is to help preserve those artifacts and create an Internet library for researchers, historians, and scholars.
Quora’s closure isn’t a remote, distant possibility, and as a collection of uniquely personal stories and knowledge, there’s a strong argument for preserving it. Most VC-funded social platforms eventually shutter, and in many cases, the only remnants left are what was saved by volunteer archivists and the Internet Archive.
All of Quora’s efforts to lock up its community’s contributions make it incredibly difficult to preserve when they go away, which they someday will. If you choose to contribute to Quora, they’re actively fighting to limit future access to your own work.
Burning It Down
Nearly ten years after its founding, Quora’s long-term prospects are still uncertain. They’ve raised over $225 million in four rounds of funding, most recently an $85 million Series D in April 2017 at a $1.7 billion valuation.
Their self-serve ad platform launched last year, but have yet to report earnings. This is the first time in its nine-year history it’s made any money at all, which is better than nothing, but the sustainability of its model is still a question mark.
At some point, the investors who dumped a quarter billion dollars into it will want a return on that investment. Last year, founder Adam D’Angelo indicated they expect to eventually IPO. But market conditions, combined with the results of their ad platform, may force them in different directions — a pivot, merger, or acquisition are always a possibility.
When Quora shuts down, and it will eventually shut down one day, all of that collected knowledge will be lost unless they change their isolationist ethos.
Back in 2012, Adam D’Angelo wrote, “We hope to become an internet-scale Library of Alexandria.”
As long as Quora keeps boarding up the exits, we may see it end the same way.