Earlier this month, I wrote about Tiny Awards, a tiny prize to honor websites that “best embodies the idea of a small, playful and heartfelt web.” I was invited to be a part of the inaugural award’s selection committee, and helped narrow down the 270 submissions to 16 finalists, which were then open to public voting.
This morning, Tiny Awards announced the winner: the dizzying and delicious Rotating Sandwiches by Lauren Walker. When I linked to it here back in March, I described it simply as the “best of the web, right here,” so I’m pretty happy with this result. Lauren will receive a $500 prize and a tiny trophy. Congrats!

The organizers of the award also released the full list of all 272 nominated websites, a “dizzying snapshot of the boundless creativity and artistic endeavor (and, occasionally, silliness) of the web (and, by extension, the people who make it).”
The organizers originally asked each member of the selection committee to decide on their top two picks from the full list of nominees. Given the volume, diversity, and quality of the entries, this was no easy task.
Now that the winner’s announced, I thought I’d share my own decision-making process, along with my personal list of runners-up.
I ended up eliminating several nominees because they didn’t meet the contest criteria, either because they launched long before the June 2022 cutoff date (e.g. Lynn Fisher’s wonderful Nestflix), required an app/download or subscription (e.g. Spotify-based projects), were primarily commercial or viral marketing for an agency/company, or in one unfortunate case, stole their content from another artist.
When I finally narrowed down my personal top list of contenders, I broke the tie by ranking each on the three core values that the contest was meant to highlight: the “small, heartfelt, and playful” web.
To be clear, these were just my own personal picks: each of the eight members of the selection committee contributed their top two websites, which became the shortlist of 16 finalists that everyone voted on. Here’s the email I sent to Matt and Kristoffer, the two organizers:
You have no idea how hard this was for me! Here’s my top two:
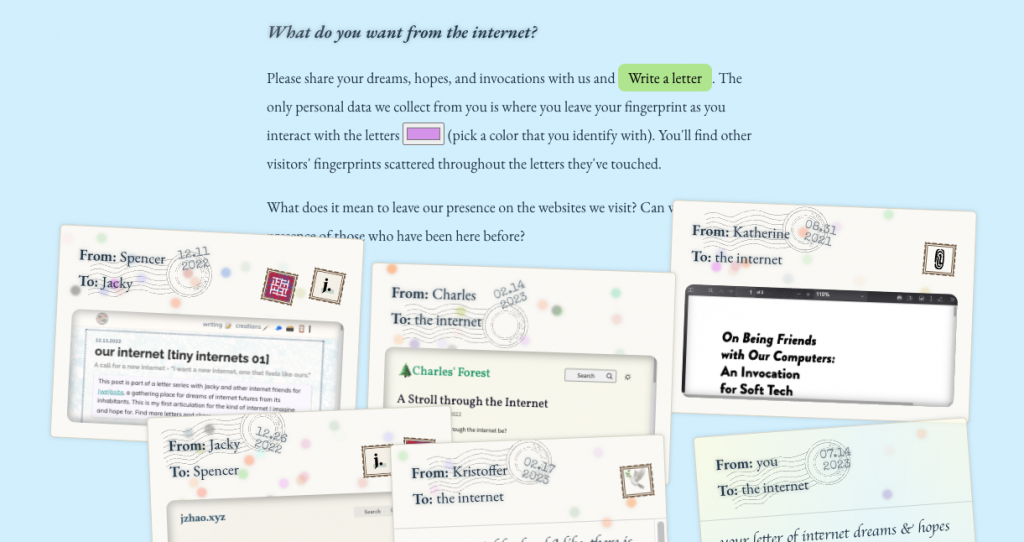
- Brr.fyi – brr.fyi. This anonymous blog came out of nowhere last year, documenting life on a research station in Antarctica, one of the most remote places on earth. But it uniquely uses the web to communicate their personal experience to the rest of the world, from mundane observations to the quietly profound. At a time where it feels like blogging has largely fallen by the wayside, this newly-launched blog (July 2022, just in time!) is a shining example of why the web is great.
- The HTML Review – thehtml.review. “An annual journal of literature made to exist on the web.” Incredibly well curated, simple and poetic experiments with HTML from 17 individual contributors. Grid World is my personal highlight (and also nominated, ranked high in my list), but really, they’re all great and special and unique. A publication worth supporting, completely non-commercial and made out of pure love of the artisanal web. I hope it goes on forever.
I had some very close runners-up, but they weren’t as 1. small, 2. heartfelt, and 3. playful as those two — usually a bit lower on one characteristic out of the three. All of them met all the criteria, including dates. But they’re all great and I love them, and it was super painful to choose!
Playful and heartfelt, but technically complex, so perhaps not “small” by many definitions:
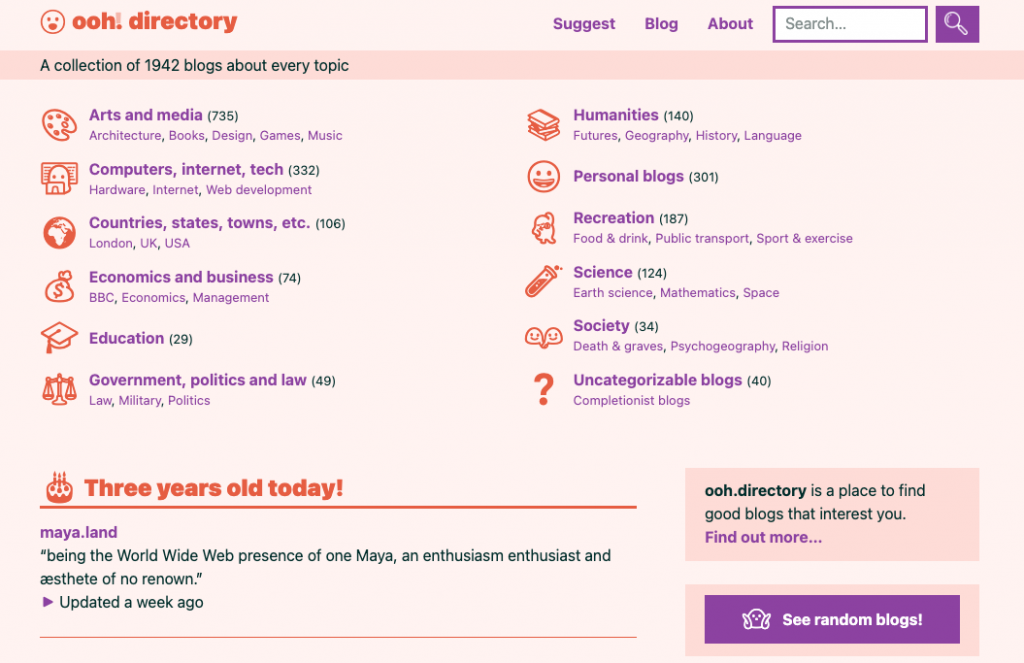
- ooh.directory – ooh.directory
- Life Universal – oimo.io/works/life
- America – 4m3ric4.com
- Infinite Mac – infinitemac.org
Small and very playful, but maybe not as “heartfelt”:
- Rotating Sandwiches – rotatingsandwiches.com
- f1f2f3f4f5f6f7f8f9 – f1f2f3f4f5f6f7f8f9.online
Smart, heartfelt, and playful, but sadly, doesn’t work well on mobile:
- Bloggy Garden – bloggy.garden
The organizers have already announced they plan to hold the award again next year, which I’m very excited about. I think it’s important to remind people that the internet is more than a bunch of apps and walled gardens made by large companies, and literally anyone can make a little website to make it better.