While trying to fix my printer today, I discovered that a PDF copy of Satoshi Nakamoto’s Bitcoin whitepaper apparently shipped with every copy of macOS since Mojave in 2018.
I’ve asked over a dozen Mac-using friends to confirm, and it was there for every one of them. The file is found in every version of macOS from Mojave (10.14.0) to the current version, Ventura (13.3), but isn’t in High Sierra (10.13) or earlier. Update: As confirmed by 9to5Mac, it was removed in macOS Ventura 13.4 beta 3.
See for Yourself
If you’re on a Mac, open a Terminal and type the following command:
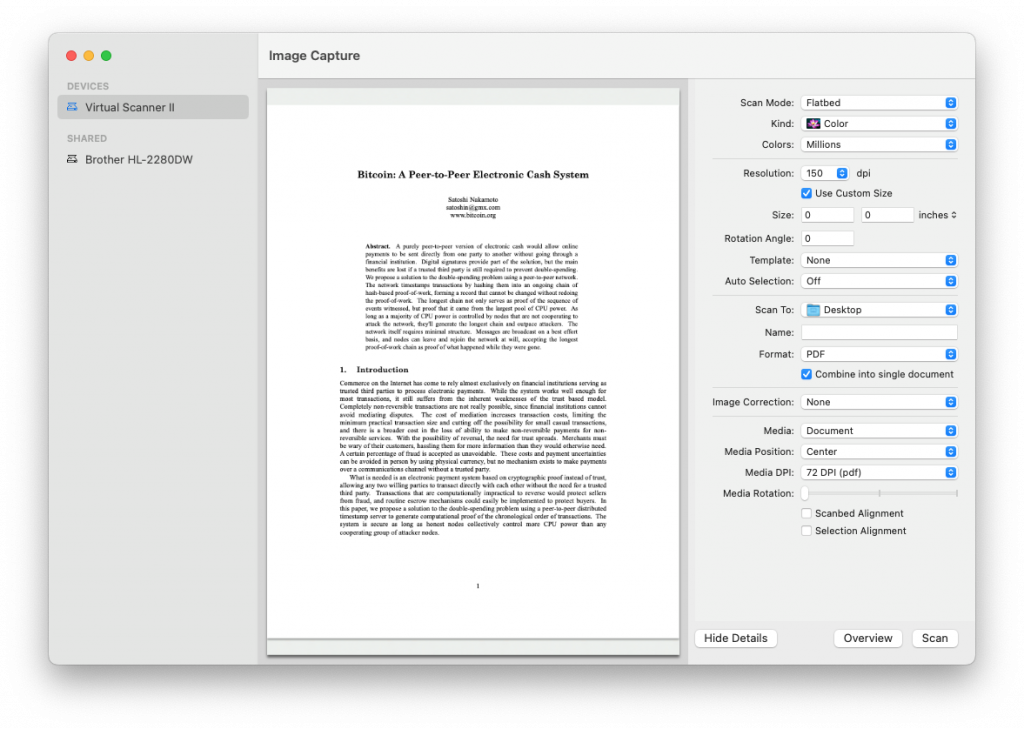
open /System/Library/Image\ Capture/Devices/VirtualScanner.app/Contents/Resources/simpledoc.pdf
If you’re on macOS 10.14 or later, the Bitcoin PDF should immediately open in Preview.
(If you’re not comfortable with Terminal, open Finder and click on Macintosh HD, then open the System→Library→Image Capture→Devices folder. Control-click on VirtualScanner.app and Show Package Contents, open the Contents→Resources folder inside, then open simpledoc.pdf.)
In the Image Capture utility, the Bitcoin whitepaper is used as a sample document for a device called “Virtual Scanner II,” which is either hidden or not installed for everyone by default. It’s not clear why it’s hidden for some or what exactly it’s used for, but Reid Beels suggested it may power the “Import from iPhone” feature.
In Image Capture, select the “Virtual Scanner II” device if it exists, and in the Details, set the Media to “Document” and Media DPI to “72 DPI.” You should see the preview of the first page of the Bitcoin paper.
But Why
Of all the documents in the world, why was the Bitcoin whitepaper chosen? Is there a secret Bitcoin maxi working at Apple? The filename is “simpledoc.pdf” and it’s only 184 KB. Maybe it was just a convenient, lightweight multipage PDF for testing purposes, never meant to be seen by end users.
There’s virtually nothing about this online. As of this moment, there are only a couple references to “Virtual Driver II” or the whitepaper file in Google results. Namely, this Twitter thread from designer Joshua Dickens in November 2020, who also spotted the whitepaper PDF, inspiring this Apple Community post in April 2021. And that’s it!
Here's a mystery: why do I have an Image Capture device called Virtual Scanner II on my Mac? It shows a preview of a painted sign that for some reason closely resembles a photo by @thomashawk on 'clustershot'? But not exactly — the scanned version looks more weathered. pic.twitter.com/jPb5kx3NyS
One other oddity: there’s a file called cover.jpg in the Resources folder used for testing the Photo media type, a 2,634×3,916 JPEG photo of a sign taken on Treasure Island in the San Francisco Bay. There’s no EXIF metadata in the file, but photographer Thomas Hawk identified it as the location of a nearly identical photo he shot in 2008.
If you know anything more — about how or why the Bitcoin paper ended up in macOS or what Virtual Scanner II is for — get in touch or leave a comment. (Anonymity guaranteed!)
Update: A little bird tells me that someone internally filed it as an issue nearly a year ago, assigned to the same engineer who put the PDF there in the first place, and that person hasn’t taken action or commented on the issue since. They’ve indicated it will likely be removed in future versions.
Update (April 26): As confirmed by 9to5Mac, it was removed in macOS Ventura 13.4 beta 3.
It’s Oscar night! Which means I’m curled up on my couch, watching the ceremony and doing data entry, updating my spreadsheet tracking the illicit distribution of Oscar-nominated films online.
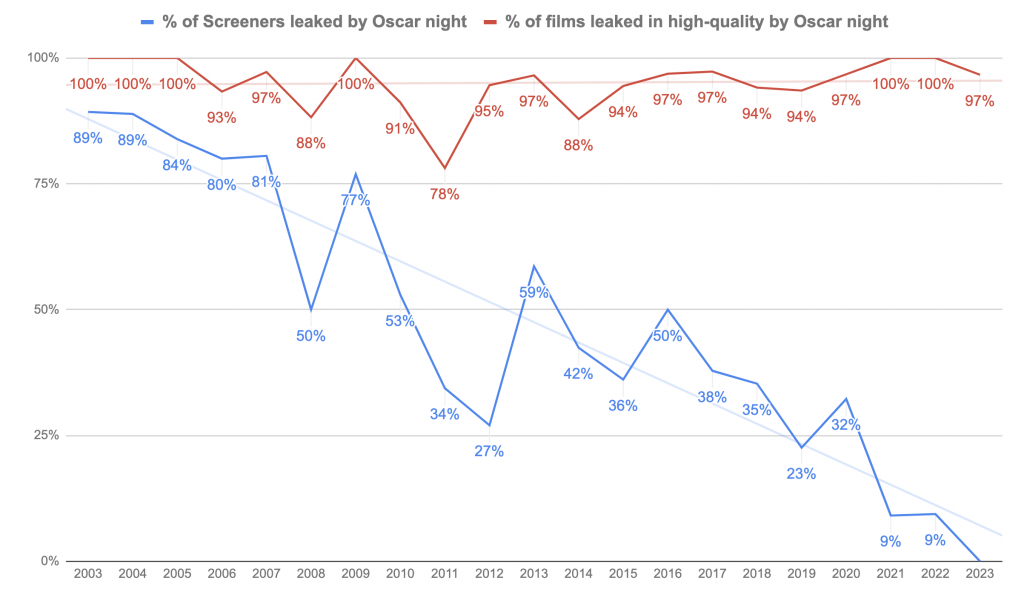
The results are in, and once again, nearly every nominee leaked online in HD quality before the broadcast. All but one of this year’s 30 nominated films leaked online — everything except Avatar: The Way of Water.
But not a single screener for a nominated film leaked by Oscar night — for the first time in the 20 years I’ve been tracking it.
What Happened?
For the first five years of the project, every year from 2003 to 2007, over 80% of screeners for nominated films made their way online. And now, not one screener leaked.
If you’ve read my past reports, you’ll know this is the culmination of a long-standing trend.
Oscar voters still get access to screeners for every nominated film, now entirely via streaming. But they typically get access to screeners after other high-quality sources for the films have appeared online: typically from other streaming services or on-demand rentals.
This is a huge difference from 20 years ago. Back then, screeners were highly-prized because they were often the only way to watch Oscar-nominated films outside of a theater. Theatrical release windows were longer, and it could take months for nominees to get a retail release.
But over time, things changed. The MPAA, often at the behest of Academy voters, was committed to the DVD format well into the 2010s, which became increasingly undesirable as 1080p and 4K sources became far more valuable than 480p resolution.
A shift from theaters to streaming meant more audiences demanded seeing movies at home, shrinking the window from theatrical release to on-demand streaming and rentals. Then the pandemic put the nail in the screener’s coffin, as people stayed home.
You can see this trend play out in the chart below, which shows the percentage of nominated films that leaked online as screeners, compared to the percentage that leaked in any other high-quality format.
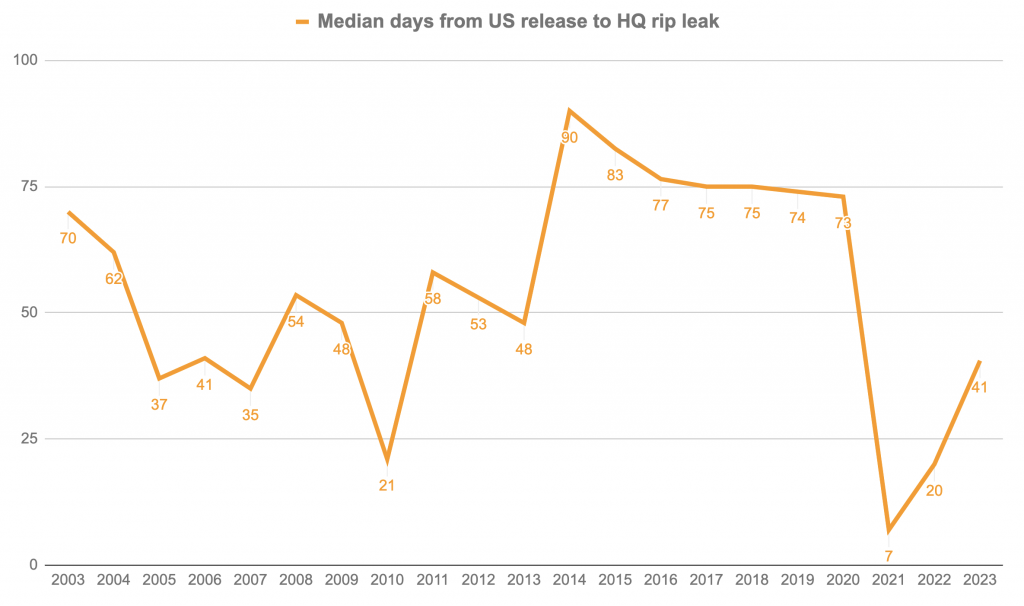
In last year’s analysis, I wondered if the time between theatrical release and the first high-quality leak online would start to increase again, as more movies return to theaters and studios experimented with returning to longer windows. That appears to have happened, as the chart below shows, but there may be another contributing factor.
Last December, Torrentfreak reported on the notable lack of screener leaks, mentioning rumors of a bust that may have taken down EVO, the scene release group responsible for the majority of screener leaks in recent years. (Update: Three days after the Oscars aired, those rumors were confirmed. Portuguese authorities arrested EVO’s leaders in November 2022.)
Regardless of the reasons, it seems clear that no release group got access to the Academy Screening Room, where voters can access every screener for streaming, or perhaps the risk of getting caught outweighed the possible return.
Closing the Curtain
In 2004, I started this project to demonstrate how screener piracy was far more widespread than the Academy believed, and I kept tracking it to see if anything the Academy did would ever stop scene release groups from leaking screeners.
In the process, this data ended up being a reflection of changes in how we consume movies: changing media formats and increasing resolution, the shift to streaming, and shrinking release windows from theaters to streaming.
I didn’t think there was anything the MPAA could do to stop screeners, and ultimately, there wasn’t. The world changed around them and made screeners largely worthless. The Oscar screener appears to be dead and buried for good, but the piracy scene lives on.
And with that, it seems like a good place to wrap this project up. The spreadsheet has all the source data, 21 years of it, with multiple sheets for statistics, charts, and methodology. Let me know if you make any interesting visualizations with it.
Thanks for following along over the years. Ahoy! 🏴☠️🍿
But after digging through Google, YouTube, Vimeo, DailyMotion, C-SPAN, and the Twitter archives myself, it seemed to be true: an iconic moment of ’90s political pop culture appeared to be completely missing from the internet.
Boxers or Briefs
If you were alive in the early ’90s, there’s a good chance you remember this moment.
During MTV’s “Choose or Lose” campaign coverage in the early ’90s, Bill Clinton promised to return to MTV if elected by the channel’s young voters. As promised, a little over a year into his first term, he appeared on MTV’s Enough is Enough on April 19, 1994, a town hall-style forum with 200 16- to 20-year-olds focused on violence in America, and particularly the 1994 crime bill being debated at the time.
Toward the end of the 90 minute broadcast, during a series of rapid-fire audience questions, 17-year-old Tisha Thompson asked a question that seemed to surprise and embarrass Clinton:
Q. Mr. President, the world’s dying to know, is it boxers or briefs? [Laughter] [Applause]
Clinton: Usually briefs. [Laughter] I can’t believe she did that.
That question got a ridiculously outsized amount of attention at the time. The Washington Post called him the “Commander In Briefs.” It was covered in the New York Times, Baltimore Sun, and countless others. It was the subject of late-night talk show monologues, and Clinton himself joked about it at the White House Correspondent’s Dinner later that week.
Over the following years, the “boxers or briefs” question became the “Free Bird” of the campaign trail, posed to Newt Gingrich (“that is a very stupid question, and it’s stupid for you to ask that question”), Bernie Sanders (“briefs”), and then-candidate Barack Obama: “I don’t answer those humiliating questions. But whichever one it is, I look good in ’em!”
Nearly 30 years later, the original clip is shockingly hard to find online. Someone on Reddit linked to a version of the video on YouTube, but the account was terminated. C-SPAN has a different clip from the show, as well as a searchable transcript, but not the clip itself.
As of right now, before I publish this post, it’s extremely hard to find online — but not impossible, because I found it, and here it is.
How I Found It
Among its voluminous archives of web pages, books, and other media, the Internet Archive stores a huge number of U.S. TV news videos, clips from over 2,470,000 shows since 2009. You can search the closed captions, and view short video clips from the results.
Their search engine is a little quirky, but more than good enough to find several news talk shows who rebroadcast the clip over the last few years, typically to poke fun at Bill Clinton. I searched for the exact quoted phrases from the original interview, and found 14 clips that mentioned it from shows like Hardball with Chris Matthews, Tucker Carlson Tonight, and The Situation Room with Wolf Blitzer.
Only one of the clips included the full question and answer, and didn’t overlay any graphics on the video, from an episode of Up w/Steve Kornicki on March 15, 2014.
The Internet Archive will let you stream the short clips, but there’s no option to download the video itself, and unfortunately, it frequently won’t show the exactly the moment you’re searching for. (This is probably an issue with alignment of closed captions and source videos.)
That said, you can edit the timestamp in the video URL. Every video result page has a URL with something like “/start/2190/end/2250” in the URL. This is the start and end timestamp in seconds, which you can adjust manually. (There appears to be a three-minute limit to clip length, so if you get an error, make sure you’re not requesting longer than that.)
Once you’ve found what you like, you can download it using Chrome Dev Tools:
First, start and then pause the video.
In Chrome, use Option-Command-C to open the element inspector in Chrome Dev Tools.
Highlight and click on the paused video.
In the Chrome Dev Tools window, right-click on the <video> tag and choose Open In New Tab.
The video will now be in a dedicated tab. Hit Ctrl-S (Command-S on Mac) to save the video, or select “Save Page As…” from the File menu.
Or in Firefox, it’s much easier: just hold shift and right-click to “Save Video.”
After that, I just cropped the clip and uploaded it to my site, and YouTube for good measure. If you have a better quality version, please send it to me.
That’s it! The Internet Archive is an amazing and under-utilized resource, poorly indexed in Google, but absolutely filled with incredible things.
Screenshot of Up w/Steve Kornicki broadcast from March 15, 2014
Updates
On May 9, 2023, Paramount announced it was shutting down MTV News permanently, 36 years after it was started. This led to a bunch of tributes and retrospectives, and many of them link to this blog post or the copy of the video I put up on YouTube.
The Hollywood Reporter’s oral history of MTV News talked to Doug Herzog, who was MTV’s first News Director and went on to become president of Viacom Music and Entertainment Group, overseeing all of MTV, VH1, and Comedy Central, among others. He casually dropped this bomb, which I don’t think has ever been reported anywhere:
HERZOG: It’s Choose or Lose — which won a Peabody in 1992 — that ultimately led to, you know, Bill Clinton coming on MTV and talking about “boxers or briefs.” That question was planted by MTV, by the way.
The young woman who asked the question, Tisha Thompson, worked at MTV News, so that tracks! I asked her if she was already an intern or employee at MTV News when she asked the question, which seems likely. I’ll update this post if I get a response.
Last weekend, Hollie Mengert woke up to an email pointing her to a Reddit thread, the first of several messages from friends and fans, informing the Los Angeles-based illustrator and character designer that she was now an AI model.
The day before, a Redditor named MysteryInc152 posted on the Stable Diffusion subreddit, “2D illustration Styles are scarce on Stable Diffusion, so I created a DreamBooth model inspired by Hollie Mengert’s work.”
Using 32 of her illustrations, MysteryInc152 fine-tuned Stable Diffusion to recreate Hollie Mengert’s style. He then released the checkpoint under an open license for anyone to use. The model uses her name as the identifier for prompts: “illustration of a princess in the forest, holliemengert artstyle,” for example.
Artwork by Hollie Mengert (left) vs. images generated with Stable Diffusion DreamBooth in her style (right)
The post sparked a debate in the comments about the ethics of fine-tuning an AI on the work of a specific living artist, even as new fine-tuned models are posted daily. The most-upvoted comment asked, “Whether it’s legal or not, how do you think this artist feels now that thousands of people can now copy her style of works almost exactly?”
Great question! How did Hollie Mengert feel about her art being used in this way, and what did MysteryInc152 think about the explosive reaction to it? I spoke to both of them to find out — but first, I wanted to understand more about how DreamBooth is changing generative image AI.
By now, we’ve all heard stories of artists who have unwillingly found their work used to train generative AI models, the frustration of being turned into a popular prompt for people to mimic you, or how Stable Diffusion was being used to generate pornographic images of celebrities.
But since its release, Stable Diffusion could really only depict the artists, celebrities, and other notable people who were popular enough to be well-represented in the model training data. Simply put, a diffusion model can’t generate images with subjects and styles that it hasn’t seen very much.
When Stable Diffusion was first released, I tried to generate images of myself, but even though there are a bunch of photos of me online, there weren’t enough for the model to understand what I looked like.
Real photos of me (left) vs. Stable Diffusion output for the prompt “portrait of andy baio” (right)
That’s true of even some famous actors and characters: while it can make a spot-on Mickey Mouse or Charlize Theron, it really struggles with Garfield and Danny DeVito. It knows that Garfield’s an orange cartoon cat and Danny DeVito’s general features and body shape, but not well enough to recognizably render either of them.
On August 26, Google AI announced DreamBooth, a technique for introducing new subjects to a pretrained text-to-image diffusion model, training it with as little as 3-5 images of a person, object, or style.
Today, along with my collaborators at @GoogleAI, we announce DreamBooth! It allows a user to generate a subject of choice (pet, object, etc.) in myriad contexts and with text-guided semantic variations! The options are endless. (Thread 👇) webpage: https://t.co/EDpIyalqiK 1/N pic.twitter.com/FhHFAMtLwS
Google’s researchers didn’t release any code, citing the potential “societal impact” risk that “malicious parties might try to use such images to mislead viewers.”
Nonetheless, 11 days later, an AWS AI engineer released the first public implementation of DreamBooth using Stable Diffusion, open-source and available to everyone. Since then, there have been several dramatic optimizations in speed, usability, and memory requirements, making it extremely accessible to fine-tune it on multiple subjects quickly and easily.
Yesterday, I used a simple YouTube tutorial and a popular Google Colab notebook to fine-tune Stable Diffusion on 30 cropped 512×512 photos of me. The entire process, start to finish, took about 20 minutes and cost me about $0.40. (You can do it for free but it takes 2-3 times as long, so I paid for a faster Colab Pro GPU.)
The result felt like I opened a door to the multiverse, like remaking that scene from Everything Everywhere All at Once, but with me instead of Michelle Yeoh.
Sample generations of me as a viking, anime, stained glass, vaporwave, Pixar character, Dali/Magritte painting, Greek statue, muppet, and Captain America
Frankly, it was shocking how little effort it took, how cheap it was, and how immediately fun the results were to play with. Unsurprisingly, a bunch of startups have popped up to make it even easier to DreamBooth yourself, including Astria, Avatar AI, and ProfilePicture.ai.
But, of course, there’s nothing stopping you from using DreamBooth on someone, or something, else.
I talked to Hollie Mengert about her experience last week. “My initial reaction was that it felt invasive that my name was on this tool, I didn’t know anything about it and wasn’t asked about it,” she said. “If I had been asked if they could do this, I wouldn’t have said yes.”
She couldn’t have granted permission to use all the images, even if she wanted to. “I noticed a lot of images that were fed to the AI were things that I did for clients like Disney and Penguin Random House. They paid me to make those images for them and they now own those images. I never post those images without their permission, and nobody else should be able to use them without their permission either. So even if he had asked me and said, can I use these? I couldn’t have told him yes to those.”
She had concerns that the fine-tuned model was associated with her name, in part because it didn’t really represent what makes her work unique.
“What I pride myself on as an artist are authentic expressions, appealing design, and relatable characters. And I feel like that is something that I see AI, in general, struggle with most of all,” Hollie said.
Four of Hollie’s illustrations used to train the AI model (left) and sample AI output (right)
“I feel like AI can kind of mimic brush textures and rendering, and pick up on some colors and shapes, but that’s not necessarily what makes you really hireable as an illustrator or designer. If you think about it, the rendering, brushstrokes, and colors are the most surface-level area of art. I think what people will ultimately connect to in art is a lovable, relatable character. And I’m seeing AI struggling with that.”
“As far as the characters, I didn’t see myself in it. I didn’t personally see the AI making decisions that that I would make, so I did feel distance from the results. Some of that frustrated me because it feels like it isn’t actually mimicking my style, and yet my name is still part of the tool.”
She wondered if the model’s creator simply didn’t think of her as a person. “I kind of feel like when they created the tool, they were thinking of me as more of a brand or something, rather than a person who worked on their art and tried to hone things, and that certain things that I illustrate are a reflection of my life and experiences that I’ve had. Because I don’t think if a person was thinking about it that way that they would have done it. I think it’s much easier to just convince yourself that you’re training it to be like an art style, but there’s like a person behind that art style.”
“For me, personally, it feels like someone’s taking work that I’ve done, you know, things that I’ve learned — I’ve been a working artist since I graduated art school in 2011 — and is using it to create art that that I didn’t consent to and didn’t give permission for,” she said. “I think the biggest thing for me is just that my name is attached to it. Because it’s one thing to be like, this is a stylized image creator. Then if people make something weird with it, something that doesn’t look like me, then I have some distance from it. But to have my name on it is ultimately very uncomfortable and invasive for me.”
I reached out to MysteryInc152 on Reddit to see if they’d be willing to talk about their work, and we set up a call.
MysteryInc152 is Ogbogu Kalu, a Nigerian mechanical engineering student in New Brunswick, Canada. Ogbogu is a fan of fantasy novels and football, comics and animation, and now, generative AI.
His initial hope was to make a series of comic books, but knew that doing it on his own would take years, even if he had the writing and drawing skills. When he first discovered Midjourney, he got excited and realized that it could work well for his project, and then Stable Diffusion dropped.
Unlike Midjourney, Stable Diffusion was entirely free, open-source, and supported powerful creative tools like img2img, inpainting, and outpainting. It was nearly perfect, but achieving a consistent 2D comic book style was still a struggle. He first tried hypernetwork style training, without much success, but DreamBooth finally gave him the results he was looking for.
Before publishing his model, Ogbogu wasn’t familiar with Hollie Mengert’s work at all. He was helping another Stable Diffusion user on Reddit who was struggling to fine-tune a model on Hollie’s work and getting lackluster results. He refined the image training set, got to work, and published the results the following day. He told me the training process took about 2.5 hours on a GPU at Vast.ai, and cost less than $2.
Reading the Reddit thread, his stance on the ethics seemed to border on fatalism: the technology is inevitable, everyone using it is equally culpable, and any moral line is completely arbitrary. In the Reddit thread, he debated with those pointing out a difference between using Stable Diffusion as-is and fine-tuning an AI on a single living artist:
There is no argument based on morality. That’s just an arbitrary line drawn on the sand. I don’t really care if you think this is right or wrong. You either use Stable Diffusion and contribute to the destruction of the current industry or you don’t. People who think they can use [Stable Diffusion] but are the ‘good guys’ because of some funny imaginary line they’ve drawn are deceiving themselves. There is no functional difference.
On our call, I asked him what he thought about the debate. His take was very practical: he thinks it’s legal to train and use, likely to be determined fair use in court, and you can’t copyright a style. Even though you can recreate subjects and styles with high fidelity, the original images themselves aren’t stored in the Stable Diffusion model, with over 100 terabytes of images used to create a tiny 4 GB model. He also thinks it’s inevitable: Adobe is adding generative AI tools to Photoshop, Microsoft is adding an image generator to their design suite. “The technology is here, like we’ve seen countless times throughout history.”
Toward the end of our conversation, I asked, “If it’s fair use, it doesn’t really matter in the eye of the law what the artist thinks. But do you think, having done this yourself and released a model, if they don’t find flattering, should the artist have any say in how their work is used?”
He paused for a few seconds. “Yeah, that’s… that’s a different… I guess it all depends. This case is rather different in the sense that it directly uses the work of the artists themselves to replace them.” Ultimately, he thinks many of the objections to it are a misunderstanding of how it works: it’s not a form of collage, it’s creating new images and clearly transformative, more like “trying to recall a vivid memory from your past.”
“I personally think it’s transformative,” he concluded. “If it is, then I guess artists won’t really have a say in how these models get written or not.”
Images generated using the “Classic Animation” DreamBooth model trained on Disney animated films
Aside from the IP issues, it’s absolutely going to be used by bad actors: models fine-tuned on images of exes, co-workers, and, of course, popular targets of online harassment campaigns. Combining those with any of the emerging NSFW models trained on large corpuses of porn is a disturbing inevitability.
DreamBooth, like most generative AI, has incredible creative potential, as well as incredible potential for harm. Missing in most of these conversations is any discussion of consent.
The day after we spoke, Ogbogu Kalu reached out to me through Reddit to see how things went with Hollie. I said she wasn’t happy about it, that it felt invasive and she had concerns about it being associated with her name. If asked for permission, she would have said no, but she also didn’t own the rights to several of the images and couldn’t have given permission even if she wanted to.
“I figured. That’s fair enough,” he responded. “I did think about using her name as a token or not, but I figured since it was a single artist, that would be best. Didn’t want it to seem like I was training on an artist and obscuring their influence, if that makes sense. Can’t change that now unfortunately but I can make it clear she’s not involved.”
Two minutes later, he renamed the Huggingface model from hollie-mengert-artstyle to the more generic Illustration-Diffusion, and added a line to the README, “Hollie is not affiliated with this.”
After we cancelled XOXO in the early days of the pandemic, I spent much of 2020 wondering if there was any way to recreate the unique experience of a real-world festival like XOXO online: the serendipity of meeting new people while running between venues, getting drawn into conversations with strangers and old friends, stepping in and out of conversations as simply as walking away.
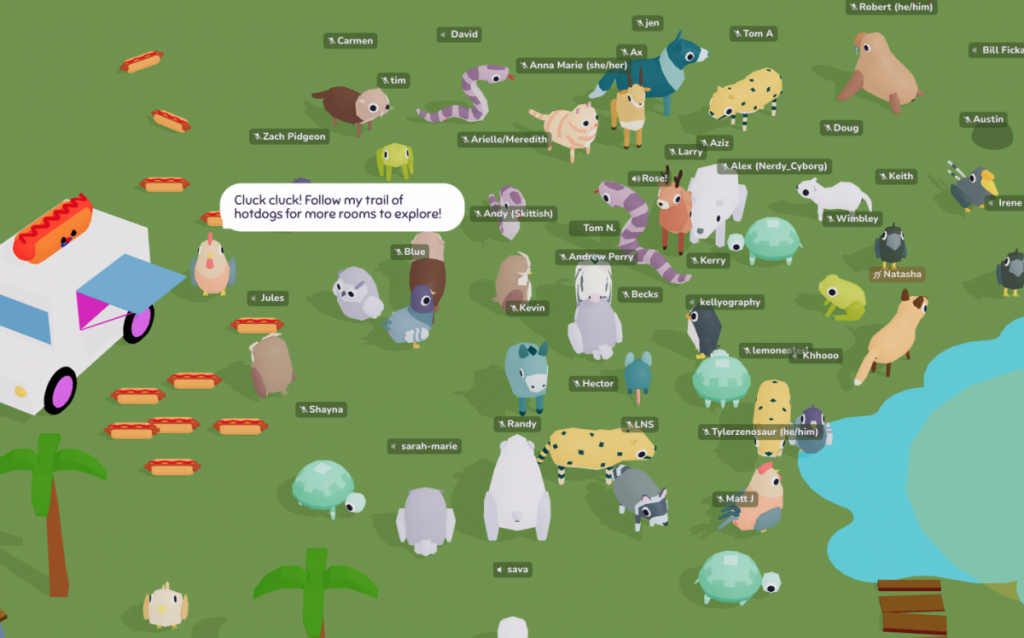
Those explorations ended up in Skittish, a colorful and customizable browser-based 3D world that let you talk to others nearby with your voice while controlling a goofy animal character. It was weird and silly and I loved it.
Sadly, for a number of reasons, I’ve decided to shut it down this December.
There isn’t enough demand to keep it going, probably a combination of an overall decline in demand for virtual events and its niche featureset, and it requires ongoing support and maintenance that’s hard for me to provide on my own.
An Exciting Beta
I’m exceedingly proud of what we built with such tight resources:
A 3D environment in the browser, fully functional on desktop and mobile browsers
High-quality spatial audio based on your location
Built-in editor for collaborative world editing
Public and private audio spaces
Embedded videos and livestreams
Roles for organizers, speakers, editors
Chat with moderation tools
Subscription payments integration with Stripe
Throughout most of last year, we ran events large and small as part of an invite-only beta. Festivals, conferences, workshops, a summer camp, and meetups of all sizes. In that first year, it got some great press from TechCrunch, The Verge, and others, and feedback was incredibly positive. It seemed like we built something that was niche, but unique and special.
A Rocky Launch
The problems started shortly after our public launch in November 2021, when we opened signups to everyone.
Two weeks in, our audio provider, High Fidelity, dealt us some devastating news: they were shutting down the spatial audio API that made Skittish possible — with only six weeks’ notice.
We scrambled to negotiate an extension with them through January 2022, eventually hosting the service on our own AWS infrastructure at great expense to prevent a disruption of service while we migrated to Dolby.io, the only other service that provided a spatial audio API.
As we were tied up with these infrastructure changes for over two months, the winds were shifting.
Waning Demand
Starting in late 2021, covid restrictions lifted virtually everywhere, and despite the pandemic raging on, event organizers were resuming in-person events.
Consequently, the demand for virtual events dropped off a cliff. This is an industry-wide trend: Hopin cut 30% of their staff, only four months after a hiring freeze and major round of layoffs. Gather laid off a third of staff and announced they were pivoting away from virtual events entirely, focusing solely on remote work collaboration. It seems like many platforms are doing the same, or quietly folding.
I still believe there are huge benefits to virtual events, especially for those devoting the time to building thoughtful social spaces like Roguelike Celebration, but the demand for virtual event platforms like ours feels very low right now, partly because we built something niche, but also simply because many people just want to meet in person now, regardless of health risk.
As our revenue dried up, we also ran out of cash. Skittish was initially funded from a grant provided by Grant for the Web, and I considered doing a small fundraise, but with the future looking so uncertain, I decided it wasn’t worth the risk.
Skittish doesn’t cost much to run without contractors, but it’s still losing money. And frankly, I’m not well-equipped to adequately support it and continue development entirely by myself.
Calling It Quits
So, as much as I love it, Skittish is winding down. I’ve already disabled upgrading to paid plans, and will disable signups on December 14. If you have unusual circumstances and need access to it longer, get in touch.
I always knew there would be risk building something like this during the pandemic. Fortunately, I built it in a way where nobody would be burned: we fully honored the terms of our grant funding, it never had investors, never took on debt, never had employees, and I’ve made sure no paying customer will be negatively affected.
I’m extremely grateful to Grant for the Web for the initial grant funding, all the events and organizations that used Skittish over the last two years, and everyone who worked on it — but especially Simon Hales for his herculean effort on every part of the platform.