Over the years, many of you long-time readers have reached out to me to send me tips or to let me know that you enjoy what I write and share here, and it always means the world to me.
Yesterday I got something notably different in my inbox, and I’m going to publish it here along with my response because I think it’s worth talking about.
Here’s the pseudonymous email I received.
Is Waxy a blog about the internet or is a blog about the personal feelings of the writer? Is it about things you find or make for the internet and share those ideas or is it just a blog where you give us your opinion of how bad Trump is then expect everyone else that reads your blog to agree with your ideas? Is it a blog about how the political right cause all the World’s problems, lead by Trump, then it is your job to let us lesser informed know of this? Is Waxy about turning a blind eye to any bad thing that the Left do so that our minds can only see the ills of the Right who, of course, are lead by Trump? I am so confused.
Is it your vocation in life to tell us how stupid we are and only to show the bumbling of the Right whilst overlooking anything the Left do? Is it that people can only make up their minds if they get biased feedback?
Waxy like so many of my once favourite sites is now only on this planet to tell me one side of the political story so that I can feel bad about myself. What is wrong with people making up their own mind based on ALL the facts or being an individual a scary concept for people with such low self esteem as many of the Left?
Why is it that 95% of us know what an idiot Trump is and most of those 95% don’t give a flying f%$# about American politics yet we have to be bombarded with all his foibles whilst hearing of the saints from the Left. I yearn for the good old days when I could follow and read my fave websites of which Waxy was one and not be bombarded with anti Trump, anti right, pro Left and bury your head in the sand and make up my own mind and not have to read the biased opinions of websites which are now just “safe places”
Disappointed.
I don’t owe anyone a reply and would normally just ignore an angry email like this. But I realized that I’ve never talked about the shift in focus that’s happened here over the last couple years, and I thought it would be worth articulating.
Here’s what I replied:
Waxy.org is, and always has been, my personal sandbox. It’s where I write and share things that I think are interesting or compelling or important that I come across online. In the past, it’s generally been things related to internet culture, copyright and fair use, the intersection of art and code, emerging technology, and the social web.
Right now, those issues just don’t matter very much to me. We’re living in a country facing a badly-mismanaged pandemic that’s killed over 200,000 Americans, a deep distrust of science and the press, the widespread rise of conspiracy theories, racist police violence, an authoritarian takeover of the federal government, a looming election crisis, and a possible civil war.
I live in the U.S., and it sounds like you don’t. That’s great for you, but I have to live here and worry about the safety, security, and future for my family and friends. Quite frankly, it’s hard to think of much else. I still link to fun internet stuff, as I always have, but it’s just one subject of several that matter very much to me right now.
As for accusations of bias, I link to articles that are factual and well-researched from authoritative sources and established publications. But I don’t think there’s “another side” to issues like the mishandling of the pandemic, systemic racism, police brutality, climate change, or the Trump administration undermining the election process. It’s the objective truth, and anything else is just spin.
I’m certainly not forcing anyone to read anything, and I share links that I think are compelling and worth reading. Feel free to read it and make up your own mind. Or unsubscribe if you can’t tolerate viewpoints that challenge your own, if it makes you feel better.
Either way, I’m not going to stop writing about issues like these until things change in this country, and I have the great luxury of focusing my attention on fun and creative things happening online.
Thanks for the feedback.
I hope that clears it up! I welcome all reader mail, anonymous or not. (Preferably nice people, but I’m not picky.) You can always email me or DM me on Twitter.
Today, research laboratory OpenAI announced Jukebox, a sophisticated neural network trained on 1.2 million songs with lyrics and metadata, capable of generated original music in the style of various artists and genres, complete with rudimentary singing and vocal mannerisms.
Introducing Jukebox, a neural net that generates music, including rudimentary singing, as raw audio in a variety of genres and artist styles. We're releasing a tool for everyone to explore the generated samples, as well as the model and code: https://t.co/EUq7hNZv62pic.twitter.com/sh5yHz7qrc
The Jukebox AI can generate new music in a genre or artist’s style, guided with lyrics and an optional audio prompt, or completely unguided.
Note that Jukebox doesn’t generate lyrics: it can only sing lyrics when they’re provided as input. Without lyrics for guidance, Jukebox generates nonsensical vocal utterances in the style of the original singer. (The lyrics in the Curated Samples section of the Jukebox announcement were generated with an unrelated language model, GPT-2, and used as playful sample input text.)
The resulting work is a clear leap forward in musical quality, though it comes with some limitations.
“While Jukebox represents a step forward in musical quality, coherence, length of audio sample, and ability to condition on artist, genre, and lyrics, there is a significant gap between these generations and human-created music.
For example, while the generated songs show local musical coherence, follow traditional chord patterns, and can even feature impressive solos, we do not hear familiar larger musical structures such as choruses that repeat.”
Just digging around the sample library, I found so many intriguing examples. It’s the uncanny valley of music: machine-hallucinated melodies and nonsensical DeepDream-esque vocals, but often capturing the style and mannerisms of the artist it’s trying to mimic.
In this example, the Jukebox AI is fed the lyrics from Eminem’s “Lose Yourself” and told to generate an entirely new song in the style of Kanye West.
With no lyrics for guidance, the AI tries to generate an entirely new David Bowie song. Have fun making out the lyrics!
Again, with no lyrics to guide it, the AI tries to generate an entirely new Prince song. I asked Anil Dash about it, and he said it sounded like it was trained heavily on Prince’s 2000s-era work.
A.I.-generated Al Green is pretty listenable. If the audio fidelity was better, I’d put this on at a dinner party. The machine-generated vocal utterances (you can’t really call them lyrics) are nonsense, but it hardly matters.
In one of the stranger examples, the OpenAI researchers fed the lyrics of Avril Lavigne’s “Dumb Blonde” to the model—and told it to make a Talking Heads song, complete with David Byrne’s vocal mannerisms.
For the Continuations collection, researchers prompted the AI with the real lyrics and first 12 seconds of the original song, and then just… let it loose. Listen to this version of David Bowie’s “Space Oddity” that rapidly goes sideways once the leash is off.
I wonder if this is what Let It Be-era Beatles sounds like to people who hate the Beatles and/or don’t speak English.
Find any great ones in the collection? Post a comment with your favorites.
Unfortunately, making your own songs won’t be as easy. While the code is available, OpenAI says it takes three hours to render 20 seconds of audio on an NVIDIA Tesla V100, a $10,000 GPU. You can experiment with it on Google Colab for short, low-quality samples, but rendering times and memory limits may make it challenging.
Legality
Just two days ago, I wrote about how Jay-Z ordered two deepfaked audio parodies off YouTube, the first known example of someone claiming copyright over an AI voice impersonation and the first time YouTube removed a video for it.
One of the OpenAI researchers on the project addressed the legality question directly, stating that they believe training the AI on copyrighted material is fair use, but sought clarification from the U.S. Patent and Trademark Office for clarification.
I'm one of the OpenAI researchers… Since this is a research project it falls under fair use (and we're not claiming copyright over the resulting samples). Agree this is a complicated area – we've written to the USPTO about this also: https://t.co/ETyCqV02li
But what about using the AI to generate new music? If I make a new album of Britney Spears songs, in her style and in her voice, who owns the copyright for that work?
I’d refer to the discussion of copyright and fair use from my earlier post, which applies here across the board. In short, it depends on how it’s used.
New music generated from a corpus of copyrighted music by a single artist may be considered a derivative work, in which case, only the original elements would be protected by copyright—and what constitutes “original” in this context? Machine-generated melodies and lyrics? The vocal performance? We’re in untested legal waters.
While there’s no federal law for personality rights, many states have recognized the right to control your likeness for commercial use, either by common law or statutes. In one notable example from 1988, Bette Midler was able to win her case against Ford Motor for their use of a sound-alike singer in advertising.
But typically, personality rights statutes would only apply to commercial uses, and not the wide array of non-commercial use for creative remixing.
Even if it’s found to be copyright infringement, the use of AI-generated music for parody, criticism, and commentary should be protected under fair use, but only a court can decide that on a case-by-case basis.
The Future Is Here
In Robin Sloan’s first novella, Annabel Scheme, a quantum computer populates a massive file server with music that never existed in this dimension.
Until this year, Annabel Scheme’s file server was the stuff of science fiction.
With the release of OpenAI’s Jukebox, the future is here and the world of music just got much, much weirder.
On Friday, I linked to several videos by Vocal Synthesis, a new YouTube channel dedicated to audio deepfakes — AI-generated speech that mimics human voices, synthesized from text by training a state-of-the-art neural network on a large corpus of audio.
According to the creator, the copyright claims were filed by Roc Nation LLC with an unusual reason for removal: “This content unlawfully uses an AI to impersonate our client’s voice.”
“Over the past few months, the creator of the channel has trained dozens of speech synthesis models based on the speech patterns of various celebrities or other prominent figures, and has used these models to generate more than one hundred videos for this channel. These videos typically feature a synthetic celebrity voice narrating some short text or a speech. Often, the particular text was selected in order to provide a funny or entertaining contrast with the celebrity’s real-life persona.
“For example, some of my favorites are George W. Bush performing a spoken-word version of “In Da Club” by 50 Cent, or Franklin Roosevelt’s powerful rendition of the Navy Seals Copypasta.
“The channel was created by an individual hobbyist with a huge amount of free time on his hands, as well as an interest in machine learning and artificial intelligence technologies. He would like to emphasize that all of the videos on this channel were intended as entertainment, and there was no malicious purpose for any of them.
“Every video, including this one, is clearly labeled as speech synthesis in both the title and description. Which brings us to the reason why we’re delivering this message.
“Over the past two days, several videos were posted to the channel featuring a synthetic Jay-Z rapping various texts, including the Navy Seals Copypasta, the Book of Genesis, the song “We Didn’t Start the Fire” by Billy Joel, and the “To Be Or Not To Be” soliloquy from Hamlet.
“Unfortunately, for the first time since the channel began, YouTube took down two of these videos yesterday as a result of a copyright strike. The strike was requested by Roc Nation LLC, with the stated reason being that it, quote, “unlawfully uses an AI to impersonate our client’s voice.”
“Obviously, Donald and I are both disappointed that Jay-Z and Roc Nation have decided to bully a small YouTuber in this way. It’s also disappointing that YouTube would choose once again to stifle creativity by reflexively siding with powerful companies over small content creators. Specifically, it’s a little ironic that YouTube would accept “AI impersonation” as a reason for a copyright strike, when Google itself has successfully argued in the case of “Authors Guild v. Google” that machine learning models trained on copyrighted material should be protected under fair use.”
No Intent to Deceive
At its core, the controversy over deepfakes is about deception and disinformation. Earlier this year, Facebook and Twitter banned deepfakes that could mislead or cause harm, largely motivated by their potential impact on the 2020 elections.
Though it’s worth nothing that the use of deepfakes for fake news is largely theoretical so far, as Samantha Cole covered for VICE, with most created for porn. (And, no, Joe Biden sticking his tongue is not a deepfake.)
In this case, there’s no deception involved. As he wrote in his statement, every Vocal Synthesis video is clearly labeled as speech synthesis in the title and description, and falls outside of YouTube’s guidelines for manipulated media.
Copyright and Fair Use
With these takedowns, Roc Nation is making two claims:
These videos are an infringing use of Jay-Z’s copyright.
The videos “unlawfully uses an AI to impersonate our client’s voice.”
But are either of these true? With a technology this new, we’re in untested legal waters.
The Vocal Synthesis audio clips were created by training a model with a large corpus of audio samples and text transcriptions. In this case, he fed Jay-Z songs and lyrics into Tacotron 2, a neural network architecture developed by Google.
It seems reasonable to assume that a model and audio generated from copyrighted audio recordings would be considered derivative works.
But is it copyright infringement? Like virtually everything in the world of copyright, it depends—on how it was used, and for what purpose.
It’s easy to imagine a court finding that many uses of this technology would infringe copyright or, in many states, publicity rights. For example, if a record producer made Jay-Z guest on a new single without his knowledge or permission, or if a startup made him endorse their new product in a commercial, they would have a clear legal recourse.
But, as the Vocal Synthesis creator pointed out, there’s a strong case to be made this derivative work should be protected as a “fair use.” Fair use can get very complicated, with different courts reaching different outcomes for very similar cases. But there are four factors judges use when weighing a fair use defense in federal court:
The purpose and character of the use.
The nature of the copyrighted work.
The amount and substantiality of the portion taken.
The effect of the use upon the potential market.
There’s a strong case for transformation with the Vocal Synthesis videos. None of the original work is used in any recognizable form—it’s not sampled in a traditional way, using an undisclosed set of vocal samples, stripped from their instrumentals and context, to generate an amalgam of the speaker.
And in most cases, it’s clearly designed as parody with an intent to entertain, not deceive. Making politicians rap, philosophers sing pop songs, or rappers recite Shakespeare pokes fun at those public personas in specific ways.
Vocal Synthesis is an anonymous and non-commercial project, not monetizing the channel with advertising and no clear financial benefit to the creator, and the impact on the market value of Jay-Z’s discography is non-existent.
There are questions about the amount and substantiality of the borrowed work. But even if the model was trained on everything Jay-Z ever produced, it wouldn’t necessarily rule out a fair use defense for parody.
Ultimately, there are two clear truths I’ve learned about fair use from my own experiences: only a court can determine fair use, and while it might be a successful defense, fair use won’t protect you from getting sued and the costs of litigating are high.
Interviewing the Creator
As far as I know, this is the most prominent example of a celebrity claiming copyright over their own deepfakes, the first example of a musician issuing a takedown of synthesized vocals, and according to the creator, the first time YouTube’s removed a video for impersonating a voice with AI. (Previously, Conde Nast took down a Kim Kardashian deepfake by claiming copyright over the source video, and Jordan Peterson ordered a voice simulator offline.)
I reached out to the anonymous creator of Vocal Synthesis to learn more about how he makes these videos, his reaction to the takedown order, and his concern over the future of speech synthesis. (Unfortunately, Roc Nation didn’t respond to a request for comment.)
How do you feel about the takedown order? Were you surprised to receive it? I was pretty surprised to receive the takedown order. As far as I’m aware, this was the first time YouTube has removed a video for impersonating a voice using AI. I’ve been posting these kind of videos for months and have not had any other videos removed for this reason. There are also several other channels making speech synthesis videos similar to mine, and I’m not aware of any of them having videos removed for this reason.
I’m not a lawyer and have not studied intellectual property law, but logically I don’t really understand why mimicking a celebrity’s voice using an AI model should be treated differently than someone naturally doing an (extremely accurate) impression of that celebrity’s voice. Especially since all of my videos are clearly labeled as speech synthesis in both the title and description, so there was no attempt to deceive anyone into thinking that these were real recordings of Jay-Z.
Can you talk a little about the effort that goes into generating a new model? For example, how long does it typically take to gather and train a new model until it sounds good enough to publish? Constructing the training set for a new voice is the most time-consuming (and by far the most tedious) part of the process. I’ve written some code to help streamline it, though, so it now usually takes me just a few hours of work (it depends on the quality of the audio and the transcript), and then there’s an additional 12 hours (approximately) needed to actually train the model.
Are you using Tacotron 2 for synthesis? Yeah, I’m using fine-tuned versions of Tacotron 2.
I saw you’ve struggled getting enough dialogue to fully develop some models, like with Mr. Rogers. Have there been other voices you’ve wanted to synthesize, but it’s just too challenging to find a corpus to work from? Yeah, several. Recently I tried to make one for Theodore Roosevelt, but there’s only about 30 minutes of audio that exists for him (and it’s pretty poor quality), so the model didn’t really come out well.
The Crocodile Hunter (Steve Irwin) is another one I really want to do, and I can find enough audio, but I haven’t been able to find any accurate transcripts or subtitles yet (it’s very tedious for me to transcribe the audio myself).
How do you decide the voices and dialogue to pair together? I try to consistently have all my voices read the Navy Seals Copypasta and the first few lines of the Book of Genesis, since it’s easier to hear the nuances of each voice when I can compare them to other voices reading the same text. Other than that, there’s no real method to it. If I have an idea for voice/text combination that I think would be funny or interesting enough to be worth the effort of making the video, then I’ll do it.
What do these videos mean to you? Is it more of a technical demonstration or a form of creative expression? I wouldn’t really consider my videos to be a technical demonstration, since I’m definitely not the first to make realistic speech synthesis impersonations of well-known voices, and also the models I’m using aren’t state-of-the-art anymore.
Mainly, I’m just making these videos for entertainment. Sometimes I just have an idea for a video that I really want to exist, and I know that if I don’t make it myself, no one else will.
On the more serious side, the other reason I made the channel was because I wanted to show that synthetic media doesn’t have to be exclusively made for malicious/evil purposes, and I think there’s currently massive amounts of untapped potential in terms of fun/entertaining uses of the technology. I think the scariness of deepfakes and synthetic media is being overblown by the media, and I’m not at all convinced that the net impact will be negative, so I hoped that my channel could be a counterexample to that narrative.
Are you worried about the legal future for creative uses of this technology? Sure. I expect that this technology will improve even more over the next few years, both in terms of accuracy and ease of use/accessibility. Right now it seems to be legally uncharted waters in some ways, but I think these issues will need to be settled fairly soon. Hopefully the technology won’t be stifled by overly restrictive legal interpretations.
It seems inevitable that, at some point, an artist’s voice is going to be used for other uses against their will: guesting on a track without permission, promoting products they aren’t paid for, or maybe just saying things they don’t believe. What would you say to artists or other public figures who are worried that this technology will damage their rights and image? There are always trade-offs whenever a new technology is developed. There are no technologies that can be used exclusively for good; in the hands of bad people, anything can be used maliciously. I believe that there are a lot of potential positive uses of this technology, especially as it gets more advanced. It’s possible I’m wrong, but for now at least I’m not convinced that the potential negative uses will outweigh that.
Update: I just heard from Vocal Synthesis’s creator that the copyright strike was removed, and bothvideos are back on his channel. I initially suspected that Roc Nation dropped the copyright claim, but Nick Statt at The Vergereported that Google reviewed the DMCA takedowns.
“After reviewing the DMCA takedown requests for the videos in question, we determined that they were incomplete,” a Google spokesperson tells The Verge. “Pending additional information from the claimant, we have temporarily reinstated the videos.”
If Roc Nation provides the missing information to complete the DMCA requests, the videos will go offline again. Or, given the press coverage, they may choose to let it go. We’ll see!
That tweet kicked off a paste party with over 2,000 replies, a potpourri of pure chaos and joy.
Random strings from emails and chat, passwords and 2FA tokens to unknown apps, screenshots and photos, obscure Unicode characters, dollar amounts from spreadsheets, bits of text in languages from Python to Esperanto, and so many links to articles, songs, videos, tweets, and obscure web pages.
It’s a momentary snapshot of digital ephemera, to be used and immediately discarded, much of it never meant to be seen by anyone and stripped of all context.
I first saw this idea in a private file-sharing/discussion community, and tried it on Twitter back in 2012, giving away copies of games and movies to people who replied with the contents of their clipboard. (Those attempts netted 14 and 24 replies, respectively, but Twitter won’t show threaded replies for older tweets.)
But the idea goes back much further. Discussion forums and message boards have played variations of the “Ctrl+V Game” (or “Ctrl+V Threads”) since at least the early 2000s. Some of them ran for years, like this 12-year-long thread from Ants Marching with 4,500 replies.
The earliest examples I found are this Usenet thread from May 2001 (thanks, Ben!) and this thread from October 2001, but pre-2001 digital archives are hard to search these days. I wouldn’t be surprised if this idea went back to forums, Usenet, and BBSes in the ’80s or ’90s. (Add a comment if you know more!)
5. Try to focus on the present. In my divorce I spent a lot of time and energy both running post mortems in my head, trying to figure out how things had gotten to this point, and worrying about what my life would look like when it was over.
It’s a great way to discover interesting links to music, video, articles, and web pages, because if it was in someone’s clipboard, it probably means they found it interesting enough to send to someone.
Wife just found out her uncle died from kidney failure after contracting the coronavirus. They were estranged and she's doing okay, but I think we're all going to end up knowing at least one person this killed.
This tiny peek into everyone’s lives — their work, interests, and concerns, or even just the mundane momentary ephemera that’s forgotten two seconds later — is the perfect birthday gift.
Three years ago, my wife Ami designed and developed her first game, a charming conversational card game called You Think You Know Me, which went on to sell over 9,000 copies around the world and now close to selling out its second print run.
I loved helping out with the package and card design for You Think You Know Me, a return to my pre-web career in desktop publishing and print production, as well as making the official homepage to support it. (The cards are all CSS!)
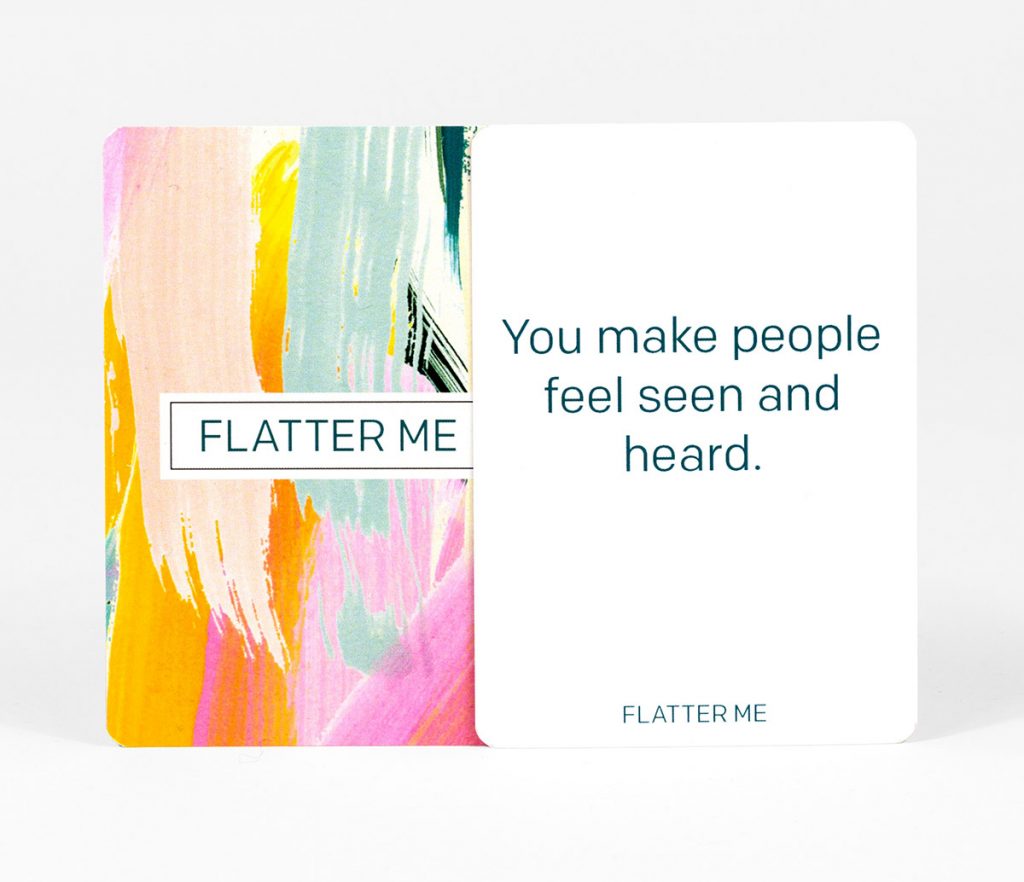
The followup to her first game is Flatter Me, a new game where you compete with friends to give compliments, with rules similar to the classic card game of War. It takes literally seconds to learn, explained in full in the project video below.
Each of the 250 cards have a unique compliment on them, which you can give away as little tokens of affection.
Once again, I helped out with the packaging and card designs, and if it hits its goal, you can expect to see a site at flatterme.cards once it’s officially on sale.
I know I’m biased, but Ami’s games have a gentle sweetness that really resonates with me. They’re all designed to bring people together, whether it’s by learning more about people you love or simply by telling them how much they mean to you.
Her games have rules and win conditions like any other card game, but they’re so quick and easy to understand that they become a convenient framework to enrich the connections between friends, family, and partners.
Flatter Me is now funding on Kickstarter, currently at 95% funded (!) with three days to go, and I’d love it if you checked it out or helped spread the word. Thanks!
If you’ve ever looked at the replies on any newsworthy amateur video posted to Twitter, you’ll see an inevitable chorus of news organizations and broadcast journalists in the replies, usually asking two questions:
Did you shoot this video?
Can we use it on all our platforms, affiliates, etc with credit?
That gave me an idea, which I posted to Twitter.
I bet you could make a great breaking news site that just monitors this Twitter search of media properties asking for permission to broadcast user videos, and scoops them by automatically posting the most active videos. https://t.co/xP3160ezHQ
I’ve returned regularly since Corey launched it and, as expected, it’s a powerful way of tracking a particular type of breaking news: visual stories with footage captured by normal people at the right place and right time.
Much of it is of interest only to local news channels: traffic accidents, subway mishaps, a wild animal on the loose, the occasional building fire.
But frequently, Bbbreaking News shows the impact of gun violence and climate change: a near-constant stream of active shooter scenarios, interspersed with massive brush fires, catastrophic flooding, and extreme weather events.
It’s a fascinating way to see the stories that broadcast media is currently tracking and viewing their sources before they can even report on it, captured by the people stuck in the middle.
I recommend checking it out. Thanks to Corey for running with the idea and saving me the effort of building it myself!
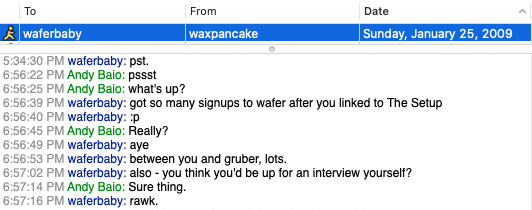
On January 22, 2009, I linked to Daniel Bogan’s newly-launched Uses This (then called “The Setup”), an interview series where he asks interesting people about “the tools and techniques they use to get things done.”
Three days later, Daniel asked me on AOL Instant Messenger if I’d be open to doing an interview myself.
I happily agreed—and then waited nearly 11 years to get around to it, despite his occasional prodding.
Yesterday, an artist on Twitter named Nana ran an experiment to test a theory.
hey can y'all do me a favor and quote tweet/reply to this with something along the lines of 'I want this on a shirt', thank you pic.twitter.com/UhuGRQgU6b
Their suspicion was that bots were actively looking on Twitter for phrases like “I want this on a shirt” or “This needs to be a t-shirt,” automatically scraping the quoted images, and instantly selling them without permission as print-on-demand t-shirts.
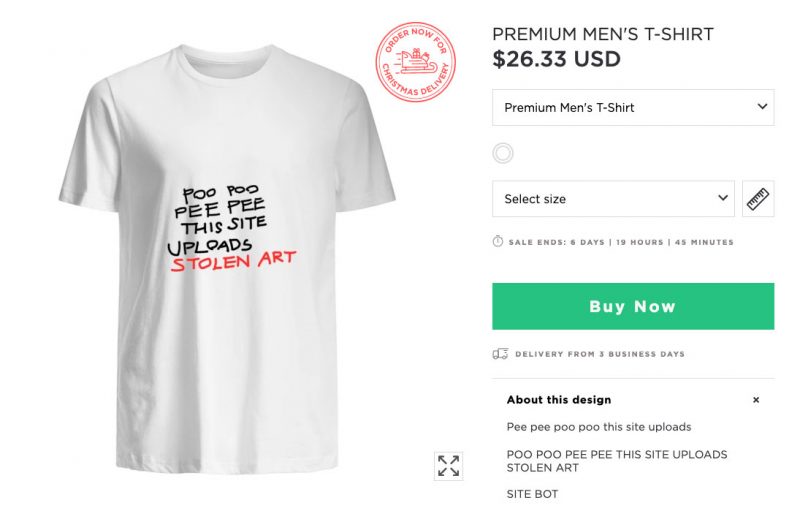
Dozens of Nana’s followers replied, and a few hours later, a Twitter bot replied with a link to the newly-created t-shirt listing on Moteefe, a print-on-demand t-shirt service.
Several other t-shirt listings followed shortly after, with listings on questionable sites like Toucan Style, CopThis, and many more.
Spinning up a print-on-demand stores is dead simple with platforms like GearBubble, Printly, Printful, GearLaunch (who power Toucan Style), and many more — creating a storefront with thousands of theoretical product listings, but with merchandise only manufactured on demand through third-party printers who handles shipping and fulfillment with no inventory.
Many of them integrate with other providers, allowing these non-existent products to immediately appear on eBay, Amazon, Etsy, and other stores, but only manufactured when someone actually buys them.
The ease of listing products without manufacturing them is how we end up with bizarre algorithmic t-shirts and entire stock photo libraries on phone cases. Even if they only generate one sale daily per 1,000 listings, that can still be a profitable business if you’re listing hundreds of thousands of items.
But whoever’s running these art theft bots found a much more profitable way of generating leads: by scanning Twitter for people specifically telling artists they’d buy a shirt with an illustration on it. The t-shirt scammers don’t have the rights to sell other people’s artwork, but they clearly don’t care.
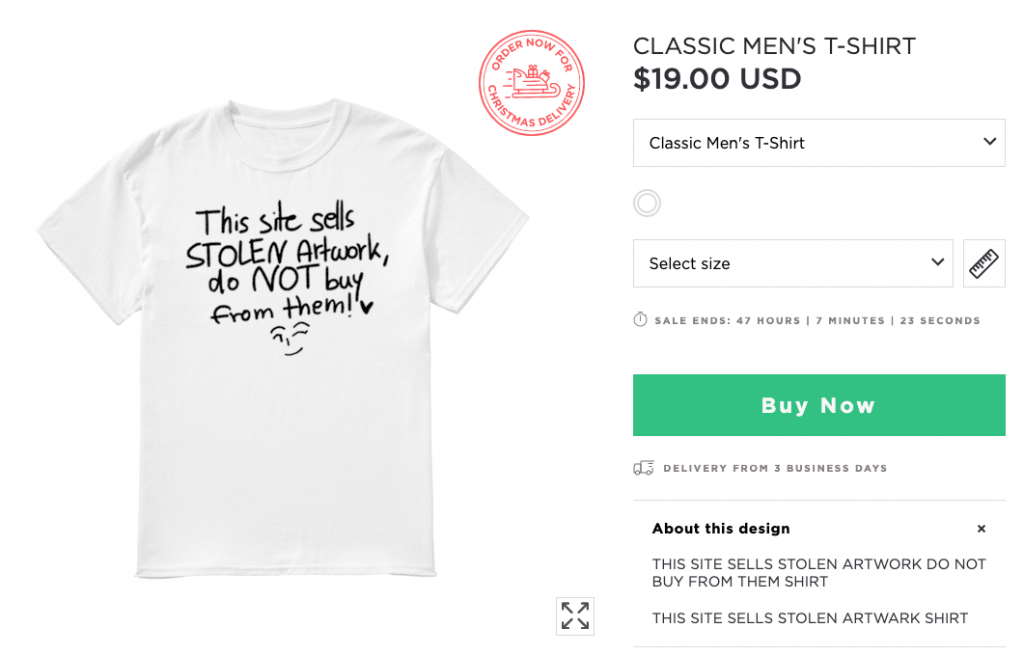
PLEASE RT: Never, ever, EVER respond to someone’s art on Twitter saying you want a shirt with that art. Bot accounts will cue into that and then pirate the artwork. This then becomes a nightmare for the artist to get the bootleg merchandise taken down. PLEASE SHARE.
What responsibility do print-on-demand providers have to prevent infringement on their platforms?
The first question is the hardest: we don’t know. These scammers are happy to continue printing shirts because their identities are well-protected, shielded by the platforms they’re working with.
I reached out to Moteefe, who seems to be the worst offender for this particular strain of art theft. Countless Twitter bots are continually spamming users with newly-created Moteefe listings, as you can see in this search.
Unlike most print-on-demand platforms like RedBubble, Moteefe doesn’t reveal any information about the user who created the shirt listings. They’re a well-funded startup in London, and have an obligation not to allow their platform to be exploited in this way. I’ll update if I hear back from them.
Until then, be careful telling artists that you want to see their work on a shirt, unless you want dozens of scammers to use it without permission.
Or feel free to use this image, courtesy of Nakanoart.
So since these art-stealing bots are tracking your text and not reply images, I made this for you guys!
If you want something from ANY creative made into a shirt, you can use this image to tell the artist you want to buy it. So you don’t need to type it out ❤️ pic.twitter.com/E9Mn2GILcb
Nearly every reply to the official @Disney account on Twitter right now is someone asking for a shirt. I wonder if their social media team has figured out what’s going on yet.
I know I shouldn’t buy them, but some of these copyright troll bait shirts are just amazing.
Starting earlier this month, the very talented Adam Koford, the creator of Laugh-Out-Loud Cats webcomic, started posting these wonderful bootleg Peanuts comics to his Twitter account, and continued almost every day since.
Loose and sketchy, they capture the essence of Charles Schultz’ Peanuts so well: sweet and sad, combining childlike wonder and existential dread. As he went on, they started evolving a unique style of their own, distinct from the Peanuts characters but still recognizable.
None of Adam’s comic tweets are threaded, making it hard to link to or catch up on, so I created this Twitter Moment aggregating them all in one place with Adam’s blessing. I embedded the whole thing below.
Needless to say, you should follow Adam on Twitter and Instagram. Just don’t tell the Peanuts estate.
Late last week, people on Twitter started noticing sponsored tweets promoting the island of Eroda, linking to a website advertising its picturesque views, marine life, and seaside cuisine.
Watch the sun rise from your bedroom window from Eroda's largest town and port.
The only catch? Eroda doesn’t exist. It’s completely fictional. Musician/photographer Austin Strifler was the first to notice, bringing attention to it in a long thread that unraveled over the last few days.
hi so i just got an ad on twitter for a place that, as far as i can tell, straight up DOES NOT EXIST (thread)
It’s dated copyright 2004, but the domain was registered on October 28 of this year.
Rotating banner ads on the site are served locally, and just point back to the Eroda homepage.
Some mysterious copy. In the description of the Eroda Ferry, “Our recommendation? Avoid leaving Eroda on odd numbered days…” For the fishing charter, “For extra good luck, make sure you wear one gold earring…” And for the Fisherman’s Pub, “The only rule of the bar? Don’t mention a pig in the pub.”
A map of the island was apparently generated in Inkarnate, an online fantasy map maker.
Two key facts indicated this was more than just one prankster’s internet goof, and that it was a well-funded viral campaign.
The Eroda site is actively running a large number of ads across Twitter, Facebook, Instagram, YouTube, and Spotify.
The visiteroda.com domain is managed by MarkMonitor, a relatively expensive service primarily used by large companies to manage and protect their domains.
The Eroda campaign continued to feed the mystery with a new YouTube video, and mysterious new posts on Twitter, Facebook, and Instagram.
The Daily Dot’s Nashwa Bawab was the first to write about the campaign, with an article on Saturday afternoon about the conspiracy theories.
Personally, I tried every trick I know to identify the owners, with no useful information. I looked at the HTML/CSS source, EXIF metadata for photos on the site, text strings in the map PDF file, IP addresses and server host, current and historical WHOIS and DNS records, reverse IP/WHOIS lookups, robots.txt, XML sitemaps, brute-forcing filenames, Google Analytics IDs, server architecture, ad tracker codes, and social network forensics.
Whoever was behind it covered their tracks well—but not well enough.
Solving the Mystery
One theory emerged from the large and obsessive Harry Styles fandom: Eroda was a promotion for Harry Styles’ upcoming album, Fine Line, due out next month on December 13.
The evidence seemed thin at first, but kept mounting. Among the clues:
Many of the photos and video from the Visit Eroda site and social media campaigns appear to have been shot in St. Abbs, a small fishing village on the southeastern coast of Scotland, the same location where Harry Styles was filming an as-yet-unreleased music video last August.
One of the cast members in the video sports a very unusual hairdo, elaborate pretzelesque braids. The About Eroda page says, “In particular, Erodean hairstyles have become a rather bold expression of self amongst the island’s youth.”
Some of the place names on Eroda may reference the song titles on the album. The Fisherman’s Pub is located “on the corner of Cherry Street and Golden Way,” while the first tracks on Sides A and B of Fine Line are called “Golden” and “Cherry.” The island’s name itself, Eroda, may be a reference to the third song, “Adore You.”
Another site launched for the new album, Do You Know Who You Are, was similarly managed by MarkMonitor, with similar coding styles for the CSS.
Any of these could be written off as coincidence.
Until last night, when Ryan J, executive producer of music magazine Down In The Pit, received a Visit Eroda ad on Facebook, and noticed that Facebook reported the ad was served to him because he’d visited Harry Styles’ official website.
This not only confirms the Eroda team is targeting Harry Styles fans, but also a clear ownership link: advertisers can only target Facebook ads to sites they’ve installed the Facebook Pixel tracker on.
In other words, Harry Styles’ official homepage and Visit Eroda are managed by the same people.
Despite all of their efforts at secrecy, the marketing agency behind this viral campaign was exposed by an unexpected source, Facebook’s ad transparency tools.
But Why?
For non-fans, this may be anti-climactic or even confusing. Why would a musician launch a viral campaign like this just to promote a new album?
ARGs and other forms of transmedia storytelling are a creative way to build a world around a piece of art, whether it’s a videogame, TV show, or album, while teasing out details for dedicated fans.
Though more common in games and TV/film, bands like Twenty One Pilots, Nine Inch Nails, and AFI have all used ARGs to promote the launch of concept albums.
For Nine Inch Nails’ Year Zero (2007), clues were hidden in concert t-shirts, USB drives left at shows, and encoded in the audio waveforms in tracks on the album itself, fleshing out Trent Reznor’s vision of the dystopian world of the concept album. The clues led to an exclusive, underground Nine Inch Nails concert for his most dedicated fans.
It’s a way for an artist to express themselves beyond the work itself, and a way to involve a community of fans, joining them together to collectively solve a mystery.
It’s too early to say where this campaign is going, but I expect we’ll know on December 13. Until then, it’s a perfect example of how impossibly hard it can be to keep a secret from a global community of dedicated fans on the internet in 2019.
Updates
December 2. Today, the Visit Eroda account tweeted the teaser trailer for Harry Styles’ “Adore You” music video, resolving the mystery for any lingering skeptics.
Since this started, I’ve participated in the Discord channel and followed each new clue and development. For me, the most interesting part was watching the cultural divide between two fandoms: ARG enthusiasts and Harry Styles stans.
The Discord team was started by ARG fans, but as Harry Styles fans joined looking for new information, it became a constant source of conflict. Admins required nearly all Harry Styles-related discussion to move out of general channels, even as evidence mounted that the campaign was promotion for his album.
Many of the ARG fans, desperate for any explanation beyond Harry Styles, constantly tried to debunk solid proof like the Facebook Pixel connection.
This morning, once the video was released and all doubt removed, it triggered a wave of frustrated farewells as dozens of members quit the Discord, while the Harry Styles fans were more excited than ever.
If the goal was to energize his fan base for the release of new material, the Eroda campaign was an unmitigated success.
I know many ARG enthusiasts were hoping for something deeper, but as someone with no interest in his music, I’m still grateful to the creative team behind the island of Eroda for making the internet just a bit more mysterious, if only for a week or two.
December 6. The full “Adore You” music video premiered this morning, telling the full story of Eroda. Great song, great video.